ref – https://www.khanacademy.org/computing/computer-science/algorithms/binary-search/a/implementing-binary-search-of-an-array
Category Archives: Uncategorized
memoize recursive functions
ref –
- https://www.digitalocean.com/community/tutorials/js-understanding-recursion
- https://medium.com/@reallygordon/implementing-memoization-in-javascript-5d140bb04166
Analysis of insertion sort
prerequisites:
- http://chineseruleof8.com/code/index.php/2017/10/11/insertion-sort/
- https://www.khanacademy.org/computing/computer-science/algorithms/insertion-sort/a/analysis-of-insertion-sort
Given
Say we’re at the last element with the number 0:
[ 2, 3, 5, 7, 11, (0) ]
In order for 0 to be sorted, it must be compared to 11. Since 11 is larger is needs to slide over 1. This goes for all elements.
Thus, every element in the array has to slide over one position to the right. Then 0 gets inserted into arr[0]…ending up with [0, 2, 3, 5, 7, 11]
If we’re inserting element n into array with k elements, we use c to denote the # of lines of code to test an element (i.e 0) against an element and slide the element over.
For example, something like this:
|
1 2 3 4 5 6 7 8 9 |
let i = arr.length-1; let toInsert = 0; while (i > 0) { let element = arr[i-1]; if (element > toInsert) { // test arr[i] = arr[i-1]; // slide over } i--; } |
then c in our case is 2 operations. But nevertheless, for implementation independent, c will simply denote the # of operations it takes to do the comparison and move the element over.
Thus, it took c * k to slide k elements over in place so that [X, 2, 3, 5, 7, 11] and finally we can insert 0 at the beginning [0, 2, 3, 5, 7, 11].
Worst case scenerio
Suppose that upon every call to insert, the value being inserted is less than every element in the subarray to its left.
Say we have [8, (5), 2, 1]
Insertion sort says, we always start index 1 (which is 5) and compare with previous element. We put 5 in a tmp variable and do a comparison, 5 < 8, so we slide over 8 over. This takes c steps and we do this 1 time. [8,8,2,1]
Then insert 5 at arr[0]
[5,8,2,1]
Then we move on to index 2, which is number 2.
[5,8,(2),1]
We do a comparison, 2 < 8, so we slide 8 over .. this is c. [5,8,8,1]
Then we compare 2 < 5, and we slide 8 over .. this is c. [5, 5, 8, 1]
Now we’re at index 0, so we simply fill it with our element 2.
[2,5,8,1]
So this is c * 2.
Then we move on to index 3, which is number 4.
We do the same comparison, and up with c * 3. Because we compare and move 1 step 3 times.
c * 1 + c * 2 + c * 3 executions.
Let’s say we start off with array [8, 7, 6 , 5, 4, 3, 2, 1]
We start at index 1 as stated by Insertion sort.
Then we work on 7. We compare and move (c) for k(1) element. So that’s c * 1. We get [7 8 6 5 4 3 2 1]
Then we work on 6. We compare and move twice for 8 and 7. So that’s c * 2. We get [6 7 8 5 4 3 2 1]
Then we work on 5. We compare and move for three times for 8 7 5. So that’s c * 3. We get [5 6 7 8 4 3 2 1]
And so on, up through the last time, when k = n-1 where n is the # of total elements.
Notice n-1. Why is that? Because we do not do compare element at index 1. We start at index 1.
Thus, what you get is:
c * 1 + c * 2 + c * 3 + c * 4 .. c * (n-1) = c(1+2+3+4…n-1)
That sum is an arithmetic series, except that it goes up to n-1, rather than n.
Arithmetic Series – Summation
Now let’s use Arithmetic series to simply and prove it.
To find the sum of the 1st n terms of an arithmetic sequence:
S = n (a initial + a of n) / 2
where n is # of terms
a initial = first term
a of n = last term
Given 5 10 15 20, let’s calculate the number of elements:
20 (last value) – 5 (first value) = 15
15 / 5 = 3
3 + 1 = 4. Add 1 to the total terms due to initial value 5.
The sum of these 4 terms are:
S = 4 (5 + 20)/2 = 2 (25) = 50
check it: 5 + 10 + 15 + 20 = 50 √
Given 2 4 6 8 10 12 14 16 18 20
S = 10 (2 + 20) / 2 = 5 (22) = 110
if you add it on the calculator, its 110 √
Say we want to go further say 2 to 222
222 – 2 = 220
220 / 2 = 110
110 + 1 = 111 Don’t forget to add 1 to 110 due to our initial value 2.
S = 111 (2 + 222)/2 = 12,432
We can also calculate term at n
A at n = initial a + (n-1)d
say we get 5 10 15 20 25
We want to figure out the 3rd term
2nd term = 5 + (2-1)(5) = 10 √
3rd term = 5 + (3-1)(5) = 15 √
5th term = 5 + (5-1)(5) = 25 √
…
…
100n term = 5 + (100-1)(5) = 500 √
The Proof
Using our formula for arithmetic series, we get that the total time spent inserting into sorted subarrays is
S = n (a initial + a of n) / 2
where # of terms n is n – 1 (remember, we don’t do the comparison for the place where we insert the value)
initial a is c * 1
last term a is c * (n – 1)
Thus, given:
c * 1 + c * 2 + c * 3 + c * 4 .. c * (n-1) =
c(1+2+3+4…n-1)
total # of terms = n-1
initial a = c*1
last term = c*(n-1)
Now we plug in everything:
S = (total # of terms) ( initial a + last term a ) / 2
S = (n-1)(c*1 + c*(n-1))/2
S = c * (n-1)(1 + n – 1) / 2
S = (c*n*(n-1)) / 2 = (cn^2)/2 – cn/2
Using O notation, we discard lower order cn/2, which leaves us (cn^2)/2
We also leave constants so we get rid of c and 1/2, which leaves us n ^ 2. Therefore, O(n^2)
Can we do it faster?
The answer is yes. Suppose we have the array [2, 3, 5, 7, 11], where the sorted subarray is the first four elements, and we’re inserting the value 11.
Upon the first comparison at index 1, we see that 3 > 2. So no need to shift. That’s c * 1.
Then we go to index 2. We see 5 > 2. So no need to shift. That’s c * 1.
This goes for 5, 7, and finally 11.
These are all constants time. Because there are n-1
This is c * (n-1), which is O(n)
So under the best case of already sorted elements, we can do O(n)
Running time of Random elements
Suppose that the array starts out in a random order. Then, on average, we’d expect that each element is less than half of the # of elements to its left. This means we expect c * (1 + 2 + 3 + … + n-1 ) / 2
The running time would be half of the worst-case running time. But in asymptotic notation, where constant coefficients don’t matter, the running time in the average case would still
be O(n^2).
Almost Sorted
What if you knew that the array was “almost sorted”: every element starts out at most some constant number of positions, say 17, from where it’s supposed to be when sorted? Then each call to insert slides at most 17 elements, and the time for one call of insert on a subarray of k elements would be at most c * 17.
Over all n-1 calls to insert, the running time would be at most 17 * c * (n-1).
which is O(n) just like the best case. So insertion sort is fast when given an almost-sorted array.
Auxiliary Space
ref – https://www.geeksforgeeks.org/g-fact-86/#:~:text=Auxiliary%20Space%20is%20the%20extra,and%20space%20used%20by%20input.
Auxiliary Space is the extra space or temporary space used by an algorithm.
Space Complexity of an algorithm is the total space taken by the algorithm with respect to the input size. Space complexity includes both Auxiliary space and space used by input
Hence, Auxiliary Space is a subset of Space Complexity.
js vs typescript
ref – https://tsh.io/blog/typescript-vs-javascript-comparison/
java instances + mac
ref – https://www.delftstack.com/howto/java/change-java-version-mac/
To see what version of Java you have installed:
/usr/libexec/java_home -V
1.8.45.14 (x86_64) “Oracle Corporation” – “Java” /Library/Internet Plug-Ins/JavaAppletPlugin.plugin/Contents/Home
1.8.0_45 (x86_64) “Oracle Corporation” – “Java SE 8” /Library/Java/JavaVirtualMachines/jdk1.8.0_45.jdk/Contents/Home
In my case, when I decided to install an older version of JDK (jdk-8u45-macosx-x64), it installed at
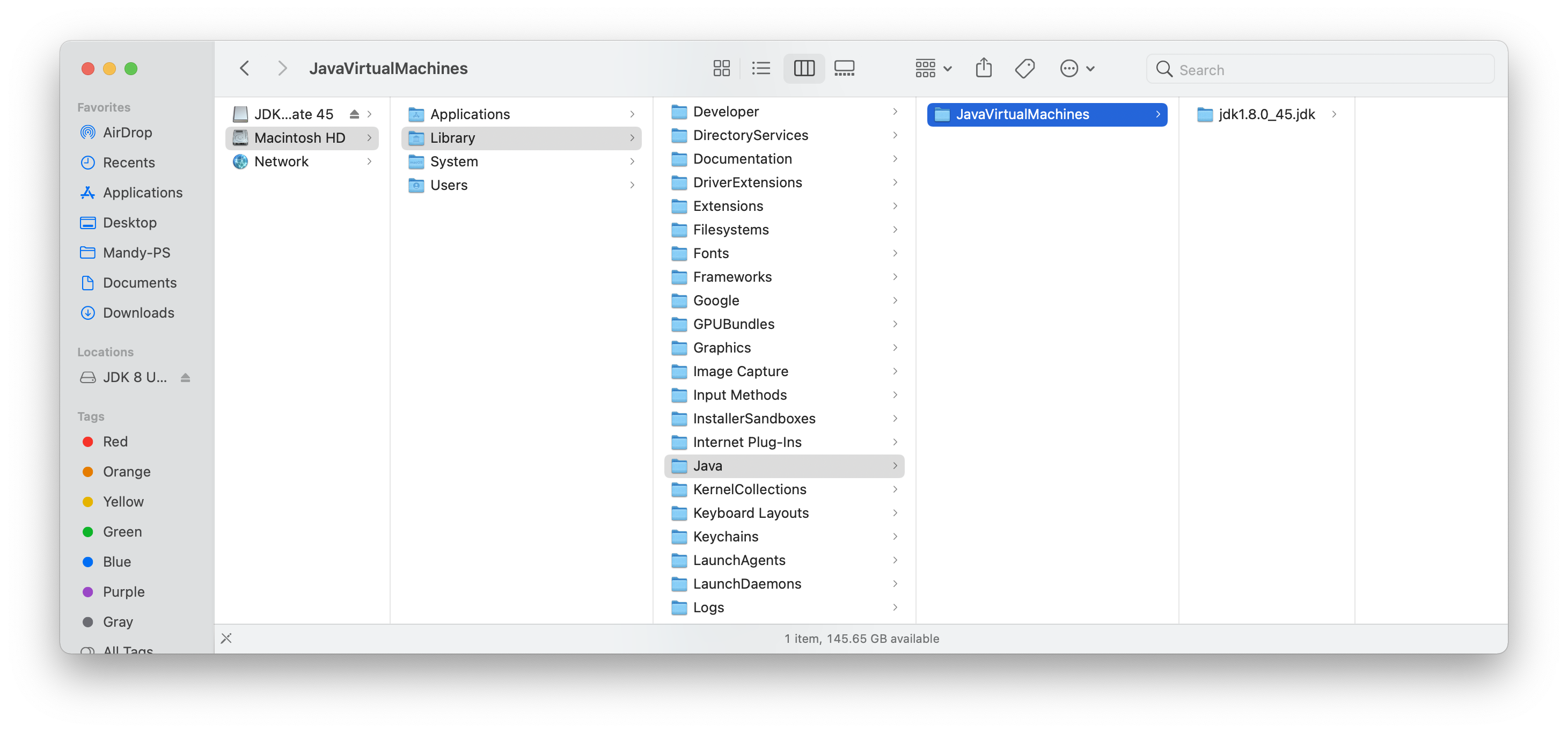
java -version (note one dash)
java version “1.8.0_45”
Java(TM) SE Runtime Environment (build 1.8.0_45-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.45-b02, mixed mode)
So I’m using 1.8.0
Sometimes, it installs in other locations:
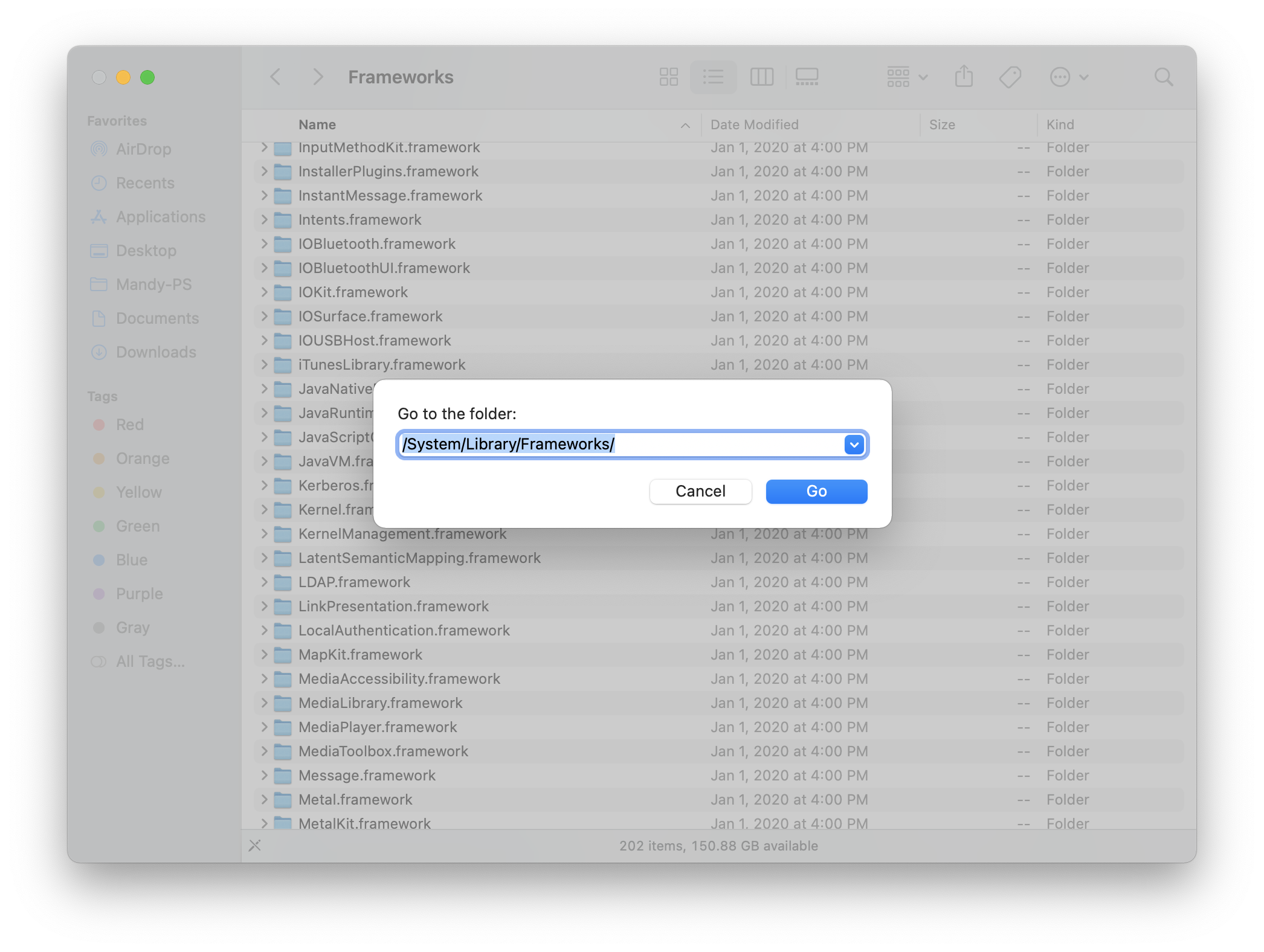
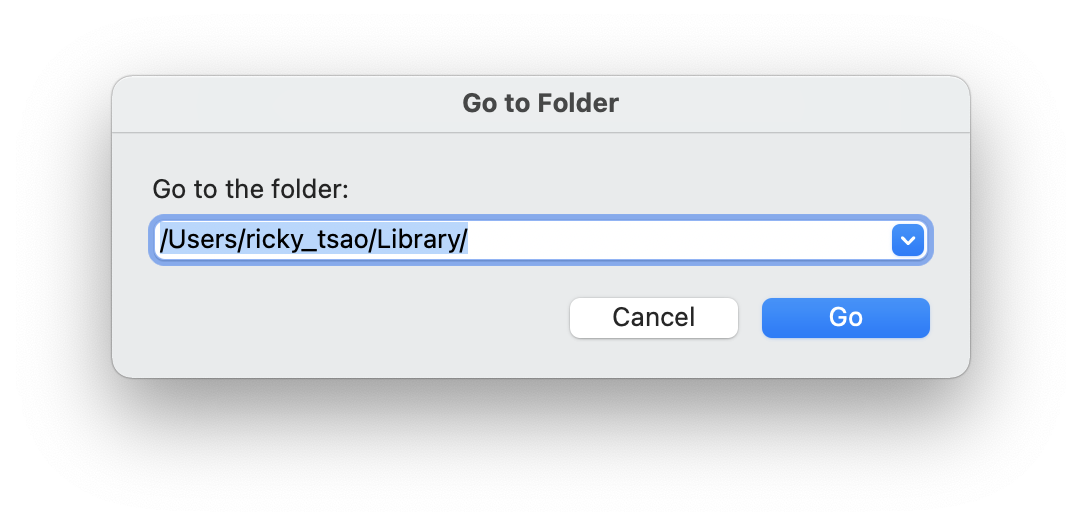
Setting up Java Env and Android emulator on Mac env
- https://blog.logrocket.com/run-react-native-apps-android-emulator-macos/
- https://javarepos.com/lib/jenv-jenv-java-general-utility-functions
brew install jenv
Updating Homebrew…
==> Downloading https://ghcr.io/v2/homebrew/portable-ruby/portable-ruby/blobs/sha256:0cb1cc7af109437fe0e020c9f3b7b95c3c709b140bde9f991ad2c1433496dd42
######################################################################### 100.0%
==> Pouring portable-ruby-2.6.8.yosemite.bottle.tar.gz
==> Auto-updated Homebrew!
After the command completes, we must tell our system where to look so it can use jenv, so we need to add it to our path. To do this, we must run the following command in our terminal:
echo ‘export PATH=”$HOME/.jenv/bin:$PATH”‘ >> ~/.zshrc
echo ‘eval “$(jenv init -)”‘ >> ~/.zshrc
We want to install JDK8 because that’s the version that works with our Android SDK Manager. Type the following into the terminal:
brew install adoptopenjdk8
brew install homebrew/cask-versions/adoptopenjdk8
This will install the latest version of Java 8 to a special directory in macOS. Let’s see which directory that is:
ls -1 /Library/Java/JavaVirtualMachines
adoptopenjdk-8.jdk
jenv add /Library/Java/JavaVirtualMachines/adoptopenjdk-8.jdk/Contents/Home/
openjdk64-1.8.0.292 added
1.8.0.292 added
1.8 added
jenv versions
system
1.8
1.8.0.292
15
15.0
* 15.0.2 (set by /Users/ricky_tsao/.java-version)
openjdk64-1.8.0.292
openjdk64-15.0.2
jenv info java
Jenv will exec : /Users/ricky_tsao/.jenv/versions/15.0.2/bin/java
Exported variables :
JAVA_HOME=/Users/ricky_tsao/.jenv/versions/15.0.2
java –version
openjdk 15.0.2 2021-01-19
OpenJDK Runtime Environment (build 15.0.2+7-27)
OpenJDK 64-Bit Server VM (build 15.0.2+7-27, mixed mode, sharing)
jenv doctor
[OK] No JAVA_HOME set
[OK] Java binaries in path are jenv shims
[OK] Jenv is correctly loaded
Protected: How to test Result and Dividends
Function Composition (functional programming)
ref – http://chineseruleof8.com/code/index.php/2019/01/03/functions-are-first-class-objects-js/
function vs procedure
Procedure – collection of functionalities.
May or may not have input, or return values, and have multiple tasks.
Functions – Mathematical functions.
- Have input
- Return value
- Simplified to a single task
- Easy for reuse
Step 1
We first have a string literal.
We have a function called prepareString.
And by scope, it reference the str and trims it for str1.
Then str1 replaces it with regex for str2.
Finally str2 upper cases everything for str3.
str3 then splits into an array.
Finally we loop through this array and try to find A, AN, or THE. If its found, delete it using splice.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
let str = 'Innovation distinguishes between a leader and a follower.'; let prepareString = function() { let str1 = str.trim(); let str2 = str1.replace(/[?.,!]/g,''); let str3 = str2.toUpperCase(); let arr = str3.split(" "); for (let i = 0; i < arr.length; i++) { if (arr[i] === 'A' || arr[i] === 'AN' || arr[i] === 'THE') { arr.splice(i,1); } } return arr; }; |
Step 2 – separate them into one task functions
|
1 |
let str1 = str.trim(); |
becomes
|
1 2 3 |
const trim = function(str) { return str.replace(/^\s*|\s*$/g, ''); } |
|
1 |
let str2 = str1.replace(/[?.,!]/g,''); |
becomes
|
1 2 3 |
const noPunct = function(str) { return str.replace(/[?.,!]/g,''); } |
|
1 |
let str3 = str2.toUpperCase(); |
becomes
|
1 2 3 |
const capitalize = function(str) { return str.toUpperCase(); } |
|
1 |
let arr = str3.split(" "); |
becomes
|
1 2 3 |
const breakout = function(str) { return str.split(" "); } |
|
1 |
if (arr[i] === 'A' || arr[i] === 'AN' || arr[i] === 'THE') |
becomes
|
1 2 3 |
const noArticles = function(str) { return (str !== "A" && str !== "AN" && str !== "THE"); } |
Using noArticles:
|
1 2 3 4 5 |
for (let i = 0; i < arr.length; i++) { if (arr[i] === 'A' || arr[i] === 'AN' || arr[i] === 'THE') { arr.splice(i,1); } } |
becomes
|
1 2 3 |
const filterArticles = function(arr) { return arr.filter(noArticles); } |
Step 3
Then we need to change these functions into arrow functions.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
str = 'Innovation distinguishes between a leader and a follower.'; const trim = str => str.replace(/^\s*|\s*$/g, ''); const noPunct = str => str.replace(/[?.,!]/g,''); const capitalize = str => str.toUpperCase(); const breakout = str => str.split(" "); const noArticles = str => (str !== "A" && str !== "AN" && str !== "THE"); const filterArticles = arr => arr.filter(noArticles); |
Step 4 – Optionally call them together
|
1 |
console.log(filterArticles(breakout(capitalize(noPunct(trim(str)))))); |
pipe
The pipe function goes through each function and applies the accumulator string to each function..starting with the initiator x.
So if x is ‘word’, and the first function is !${param}, this will return ‘!word’.
Then the 2nd function is *${param}, then we’d get ‘*!word’.
Basically, it would apply the result of the current function to the param of the next function.
Notice our spread operators in the parameter. Its taking all the params together and bringing them together as the array fns.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
const pipe = function(...fns) { return function(x) { const result = fns.reduce(function(v, f) { // f is the function that returns a string // v is the accumulated string. const res = f(v); return res; }, x); // x is the starting string return result; } }; const money = param => `$${param}`; const exclamation = param => `!${param}`; const wrapper = param => `(${param})`; const star = param => `*${param}`; const rightArrow = param => `${param}-->`; const leftArrow = param => `<--${param}`; // notice how it is much easier to read const result = pipe( money, exclamation, wrapper, star, rightArrow, leftArrow); result('word'); |
Our output would be:
$word
!$word
(!$word)
*(!$word)
*(!$word)–>
<--*(!$word)-->
We can also start from the right function, (by using reduceRight) so now our output would like this:
<--word
<--word-->
*<--word-->
(*<--word-->)
!(*<--word-->)
$!(*<--word-->)
Now, going back to our work, we would stick each function to process on the string. Then use the returned string as the input for the next function. Literally, the functions put together act as a pipe for strings to go through and be processed.
|
1 2 3 4 5 6 |
const prepareString = pipe( trim, noPunct, capitalize, breakout, filterArticles); |
Function Composition 2
Given…
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
const pipe = function(...fns) { return function(x) { return fns.reduce(function(v, f) { return f(v); }, x); } }; const compose = function(...fns) { return function(x) { return fns.reduceRight(function(v, f) { return f(v); }, x); } }; |
and situation is:
|
1 2 3 4 5 6 |
const scores = [50, 6, 100, 0, 10, 75, 8, 60, 90, 80, 0, 30, 110]; const boostSingleScores = scores.map(val => (val < 10) ? val * 10 : val); const rmvOverScores = boostSingleScores.filter(val => val <= 100); const rmvZeroScores = rmvOverScores.filter(val => val > 0); const scoresSum = rmvZeroScores.reduce((sum, val) => sum + val, 0); const scoresCnt = rmvZeroScores.reduce((cnt, val) => cnt + 1, 0); |
1) Convert each statement to a function that can accept and act on any array.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
const scores = [50, 6, 100, 0, 10, 75, 8, 60, 90, 80, 0, 30, 110]; const singleScoreByTen = function (arr) { return arr.map(val => (val < 10) ? val * 10 : val); } const rmvOverScores = function(arr) { return arr.filter(val => val <= 100); } const rmvZeroScores = function(arr) { return arr.filter(val => val > 0); } const scoresSum = function(arr) { return arr.reduce((sum, val) => sum + val, 0); } const scoresCnt = function(arr) { return arr.reduce((cnt, val) => cnt + 1, 0); } |
2) Compose a function that will remove both zero or lower scores and scores over 100. Test it using the scores array.
|
1 2 |
const removeZeroAndOver = pipe(rmvOverScores, rmvOverScores); removeZeroAndOver(scores); |
3) Compose a function that will do all the modifications to an array. Test it using the scores array.
|
1 2 |
const allMod = pipe(removeZeroAndOver, singleScoreByTen); allMod(scores); |
4) Create a function that will accept an array and return the average. Use the function that sums scores and the function that counts scores or the length property.
|
1 |
const average = (scores) => scoresSum(scores) / scores.length; |
5) Compose a function that will do all the modifications on an array and return an average.
|
1 2 |
const average = pipe(allMod, scoresCnt); average(scores); |
Arity
So we still have our pipe function. Remember that it takes in an array of functions, and an initial string x. (Henry)
It goes through the first function and gives ‘Henry’ as the first parameter. The return value of the 1st function (user object) is then inserted into the 2nd function.
The return value of the 2nd function is then inserted into the 3rd function, so on and so forth.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
const pipe = function(...fns) { console.log(`We are going to go through ${fns.length} functions`); return function(x) { console.log(`starting variable is ${x}`); const result = fns.reduce(function(result, f) { // f is the function that returns a string // result is the initial input, and each subsequent input. console.log(`-- ${f.name} -- input: `, result); const res = f(result); console.log('returned', res); return res; }, x); // x is the starting string return result; } }; |
users array is the data that will be bind to getUsers function.
|
1 |
const users = [{name: "James",score: 30,tries: 1}, {name: "Mary", score: 110,tries: 4}, {name: "Henry",score: 80,tries: 3}]; |
As you can see we a function like so:
|
1 2 3 4 5 6 7 8 9 10 |
var getUser = function(arr, name) { return arr.reduce(function(obj, val) { if (val.name.toLowerCase() === name.toLowerCase()) { console.log(`found ${val.name} object!`); return val; } else { return obj; } }, null); }; |
We need to change it using bind so that we can pass in users as the data, and we get a reference to it all. That way, users is matched up to param arr.
|
1 |
const partGetUser = getUser.bind(null, users); // we pass in users array and point a reference to it. |
We get partGetUser, and then when we execute it inside pipe, we can pass in ‘Henry’ to param name of getUser.
storeUser is just a standard function.
|
1 2 3 4 5 6 7 8 9 10 |
//Modifies Data var storeUser = function(arr, user) { return arr.map(function(val) { if (val.name.toLowerCase() === user.name.toLowerCase()) { return user; } else { return val; } }); }; |
we have our cloneObj that takes an object and clones it using JSON. We leave it as is.
|
1 2 3 4 5 6 |
//Pure Functions const cloneObj = function(obj) { const clonedObj = JSON.parse(JSON.stringify(obj)); console.log(`cloned ${obj.name}`, clonedObj); return clonedObj; }; |
Then we have updateScore:
|
1 2 3 4 5 6 7 |
var updateScore = function(newAmt, user) { console.log(`Lets update score in ${user.name} to ${newAmt}`); if (user) { user.score += newAmt; return user; } }; |
we need to change it like this:
|
1 2 3 |
// const usr1 = updateScore(cloneObj(usr), 30); const partUpdateScore30 = updateScore.bind(null, 30); // we pass in the numbers, and point a reference to it. // that way, we pass in an object into the 3rd parameter later. |
updateTries is used as is.
|
1 2 3 4 5 6 7 8 9 10 |
var updateTries = function(user) { if (user) { user.tries++; return user; } }; // const usr2 = updateTries(cloneObj(usr1)); // const newArray = storeUser(users, usr2); |
We put updateUser, cloneObj, partUpdateScore30, and updateTries into our pipe utility function.
We get the result back when ‘Henry’ is inserted into the beginning of the pipe.
|
1 2 3 4 5 6 7 8 |
const updateUser = pipe( partGetUser, // we already use bind to pass in users. When executed, the string will come in as "Henry". We find "Henry" obj and pass it into cloneObj cloneObj, // then with the result, we execute cloneObj and return the cloned object. partUpdateScore30, // we then pass the cloned Object in and execute partUpdateScore30 with the obj as the next parmater after 30. It returns the user obj updateTries); // the user obj goes into the unary parameter, updates tries, and then returns the user object as result. const result = updateUser("Henry"); console.log(result); |
Arity full code
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 |
const pipe = function(...fns) { console.log(`We are going to go through ${fns.length} functions`); return function(x) { console.log(`starting variable is ${x}`); const result = fns.reduce(function(result, f) { // f is the function that returns a string // result is the initial input, and each subsequent input. console.log(`-- ${f.name} -- input: `, result); const res = f(result); console.log('returned', res); return res; }, x); // x is the starting string return result; } }; const users = [{name: "James",score: 30,tries: 1}, {name: "Mary", score: 110,tries: 4}, {name: "Henry",score: 80,tries: 3}]; //Modifies Data var storeUser = function(arr, user) { return arr.map(function(val) { if (val.name.toLowerCase() === user.name.toLowerCase()) { return user; } else { return val; } }); }; //Pure Functions const cloneObj = function(obj) { const clonedObj = JSON.parse(JSON.stringify(obj)); console.log(`cloned ${obj.name}`, clonedObj); return clonedObj; }; var getUser = function(arr, name) { return arr.reduce(function(obj, val) { if (val.name.toLowerCase() === name.toLowerCase()) { console.log(`found ${val.name} object!`); return val; } else { return obj; } }, null); }; var updateScore = function(newAmt, user) { console.log(`Lets update score in ${user.name} to ${newAmt}`); if (user) { user.score += newAmt; return user; } }; var updateTries = function(user) { if (user) { user.tries++; return user; } }; // const usr = getUser(users, "Henry"); const partGetUser = getUser.bind(null, users); // we pass in users array and point a reference to it. // that we, we pass a string name into the 3rd parameter later // const usr1 = updateScore(cloneObj(usr), 30); const partUpdateScore30 = updateScore.bind(null, 30); // we pass in the numbers, and point a reference to it. // that way, we pass in an object into the 3rd parameter later. // const usr2 = updateTries(cloneObj(usr1)); // const newArray = storeUser(users, usr2); const updateUser = pipe( partGetUser, // we already use bind to pass in users. When executed, the string will come in as "Henry". We find "Henry" obj and pass it into cloneObj cloneObj, // then with the result, we execute cloneObj and return the cloned object. partUpdateScore30, // we then pass the cloned Object in and execute partUpdateScore30 with the obj as the next parmater after 30. It returns the user obj updateTries); // the user obj goes into the unary parameter, updates tries, and then returns the user object as result. const result = updateUser("Henry"); console.log(result); |
functional programming
Building software by creating pure functions, avoid shared state, mutable data, and side-effects.
application state flows through pure functions.
Side Effects and Pure Functions
Notice the data is the array of users.
We have our mutable function that literally uses scope to access users and change its contents.
For the pure functions we take in parameters, and we do not modify these inputs. Instead, we return new arrays with shallow copied data. Notice we never touch param arr, nor name. We simply get the data we need, and return new arrays.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
var users = [{name: "James",score: 30,tries: 1}, {name: "Mary", score: 110,tries: 4}, {name: "Henry",score: 80,tries: 3}]; //Mutable Functions var recordData = function(arr, prop) { users.forEach(function(val, i, a) { if (val.name.toLowerCase() === arr[0].toLowerCase()) { a[i][prop] = arr[1]; } }); }; //Pure Functions var getScore = function(arr, name) { let score; for (let i = 0; i < arr.length; i++) { if (arr[i].name.toLowerCase() === name.toLowerCase()) { score = arr[i].score; break; } }; return [name, score]; }; var getTries = function(arr, name) { let tries; for (let i = 0; i < arr.length; i++) { if (arr[i].name.toLowerCase() === name.toLowerCase()) { tries = arr[i].tries; break; } }; return [name, tries]; }; var updateScore = function(arr, amt) { let newAmt = arr[1] + amt; return [arr[0], newAmt]; }; var updateTries = function(arr) { let newTries = arr[1] + 1; return [arr[0], newTries]; }; |
We then use the pure functions to calculate new scores.
Then give it to our mutable functions to update our data.
|
1 2 3 |
let newScore = updateScore(getScore(users, "Henry"), 30); recordData(newScore, "score"); recordData(updateTries(getTries(users, "Henry")),"tries"); |
Avoid Shared State
Javascript stores data in objects and variables. This is called state.
Notice how users are shared via closure scope. We need to void this by passing state (users)
from one function to another.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
var MAINAPP = (function(nsp) { var currentUser = 0, users = [{name: "James",score: 30,tries: 1}, {name: "Mary", score: 110,tries: 4}, {name: "Henry",score: 80,tries: 3}]; var updateScore = function(newAmt) { users[currentUser].score += newAmt; }; var returnUsers = function() { return users; }; var updateTries = function() { users[currentUser].tries++; }; var updateUser = function(newUser) { currentUser = newUser; }; nsp.updateUser = updateUser; nsp.updateTries = updateTries; nsp.updateScore = updateScore; nsp.returnUsers = returnUsers; return nsp; })(MAINAPP || {}); setTimeout(function() {MAINAPP.updateUser(2);}, 300); setTimeout(function() {MAINAPP.updateScore(20);}, 100); setTimeout(function() {MAINAPP.updateTries();}, 200); |
Mutation
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
"use strict"; const arr = [3,4,2,5,1,6]; Object.freeze(arr); const sortArray = function(arr1) { return arr1.sort(); // throw error here because we have freezed the arr object. }; const newNums = sortArray(arr); console.log(newNums); console.log(arr); |
how to avoid mutating? Clone it
|
1 2 3 4 5 6 7 8 |
let obj = { fName: "Steven", lName: "Hancock", score: 85, completion: true, }; let obj2 = Object.assign({}, obj) |
but…for objects with nested data:
|
1 2 3 4 5 6 7 8 9 10 |
let obj = { fName: "Steven", lName: "Hancock", score: 85, completion: true, questions: { q1: {success: true, value: 1}, q2: {success: false, value: 1} } }; |
we need to convert it to string, then parse it back into an object.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
const cloneObj = function(obj) { return JSON.parse(JSON.stringify(obj)); // deep clones nested object }; let obj = { fName: "Steven", lName: "Hancock", score: 85, completion: true, questions: { q1: {success: true, value: 1}, q2: {success: false, value: 1} } }; const newObj = cloneObj(obj); newObj.questions.q1 = {success: false, value: 0}; console.log(obj); console.log(newObj); |

We can do the same with arrays:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
"use strict"; const arr = [3,4,2,5,1,6]; Object.freeze(arr); const cloneObj = function(obj) { return JSON.parse(JSON.stringify(obj)); }; const newNums = cloneObj(arr).sort(); console.log(newNums); // [1,2,3,4,5,6] console.log(arr); // [3,4,2,5,1,6] |
Object.assign and spread operator works the same way.
For Arrays, spreading a null would give an error
|
1 2 |
const z = null; [...z]; |
For Objects, both silently exclude the null value with no error.
|
1 2 3 4 |
const x = null; const y = {a: 1, b: 2}; const z = {...x, ...y}; console.log(z) // {a: 1, b: 2} |
|
1 2 3 4 |
const x = null; const y = {a: 1, y:2}; const z = Object.assign({}, x, y); console.log(z); // {a: 1, b: 2} |