http://javascript.info/json
Category Archives: javascript
callback (js)
http://javascriptissexy.com/understand-javascript-callback-functions-and-use-them/
http://javascript.info/callbacks
Callbacks are reference to function that gets passed around like variables.
When we pass a callback function as an argument to another function, we are only passing the function definition. We are not executing the function in the parameter. In other words, we aren’t passing the function with the trailing pair of executing parenthesis () like we do when we are executing a function.
Note that the callback function is not executed immediately. It is “called back” (hence the name) at some specified point inside the containing function’s body.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
function functionFirst(callback) { console.log("--> functionFirst"); // 1 setTimeout(function() { console.log('Back at it again'); // after the 3 secondes, // 4 callback(); // 5 }, 3000); // the timeout here is to simulate an HTTP request or some long time operation console.log("<-- functionFirst"); // 2 } function functionSecond() { console.log('with the white Vans!'); // 8 } functionFirst(function(){ console.log("--> callback"); // 6 functionSecond(); // 7 console.log("<-- callback"); // 9 }); console.log('Damn Daniel'); // 3 |
So why is this useful? Async execution + callback
Say you send off an HTTP request and you need to do something with the response. Instead of holding up your browser, you can use a callback to handle the response whenever it arrives. In the code example above, the async execution simulated by setTimeout first counts to 3 seconds, then it executes the callback after the 3 seconds.
The only reason setTimeout is used is to simulate an async operation that takes a certain time. Such operations could be reading from a text file, downloading things or performing an HTTP request.
Callbacks are closures. As we know, closures have access to the containing function’s scope, so the callback function can access the containing functions’ variables, and even the variables from the global scope.
Also notice there is no timeOut to simulate a HTTP request or a long standing operation, thus, it will process it as is.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
var allUserData = []; //empty array function Person () { // constructor var name = "Ha Dooo Ken"; // this is a closure, it refrences local, parameters, outer, and global variables this.logStuff = function (userData) { console.log(" logStuff <--"); console.log("-- global allUserData --"); console.log(allUserData); console.log("-- outer function property 'name' -- "); console.log(name); if (typeof userData === "object") { for (var key in userData) { console.log("item: " + userData[key]); } } console.log(" logStuff -->"); } } function getInput(options, callback) { console.log("getInput <--"); console.log(callback); allUserData.push(options); // push data onto the array console.log("executing callback(option)"); callback(options); // then throw the data into the callback console.log("getInput -->"); } console.log("--- Program Start ---\n"); getInput( {name: "Ricky", specialty: "js"}, new Person().logStuff ); console.log("\n--- Program End ---"); |
output:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
--- Program Start --- getInput <-- [Function] executing callback(option) logStuff <-- -- global allUserData -- [ { name: 'Ricky', specialty: 'js' } ] -- outer property 'name' -- Ha Dooo Ken item: Ricky item: js logStuff --> getInput --> --- Program End --- |
JavaScript Event Loop
Ok, now we know what functions and callbacks are, let’s see how they get used. Let’s look at a very simple asynchronous callback example:
|
1 2 3 4 5 6 7 8 9 10 |
console.log('Before timeout'); setTimeout(function() { console.log('Timeout callback'); }, 0); console.log('After timeout'); // output: // Before timeout // After timeout // Timeout callback |
If you’re used to procedural programs, this may seem a bit strange. JavaScript is based around something called the event loop. The simple version is that JavaScript runs a loop, and on each iteration (or tick) of this loop, one event will be processed. This event could be a timeout completing, an IO operation returning, an incoming HTTP request, etc. To help with this, JavaScript utilizes a message queue.
Certain operations will insert a message into the queue (e.g. setTimeout), and if there is a handler registered for the message, it will be executed.
In our above example, on tick 1, we do the following:
Log “before timeout”
Add a message handler (the message will be added to the message queue sometime after your timeout of 0 seconds)
Log “after timeout”
Now at some point in the future, JavaScript will insert a message into the queue to call your timeout handler. This will happen on a future “tick”, and that’s why “Timeout callback” is called after the other logs.
Asynchronous operations
Since JavaScript is single threaded using an event loop, we wouldn’t want to do blocking operations (e.g. reading a file) in the main loop. This would stop the loop until the blocking operation finished, meaning none of our other code could run. While this is how many languages work in their default configuration (e.g. Ruby), JavaScript & Node.js were designed to be run as a single process using non blocking operations only.
callback references global variables also
Notice how our callback also has access the global variables.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
// global variable var generalLastName = "Tsao"; // definition of getInput function getInput(options, callback) { console.log("receiving data options, callback"); allUserData.push(options); // push data onto the array console.log(allUserData); // Make sure the callback is a function if (typeof callback === "function") { // callback references global variables also callback(generalLastName, options); } } |
More Examples
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
var gameOver = function() { console.log("You Win! Game Over"); } var tauntOpponent = function(quote) { setTimeout(function() { gameOver(); }, 2000); console.log(quote); } var hurricaneKick = function (power) { console.log("Tats Mak Sen Buuu Kyaku! psh psh psh psh"); setTimeout(function() { console.log("..opponent just lost 5X" + power + " life bars"); tauntOpponent("you must defeat sheng long to stand a chance"); }, 5000); console.log("you just executed hurricaneKick"); } let dragonPunch = function (powerLevel) { console.log("FIGHT!!"); console.log("Shoooo Ryue Ken .... !! Pppppppppsssshhhhh......"); setTimeout(function() { console.log("...opponent just lost " + powerLevel + " life bars"); hurricaneKick(20); }, 3000); console.log("you just executed dragonPunch"); } // invoking it () // as variable, do not invoke it function executeSpecialMove(power) { console.log("Round 1...."); setTimeout(dragonPunch, 2000, power); } executeSpecialMove(88); |
let vs var vs const (js)
http://javascript.info/var
https://stackoverflow.com/questions/762011/whats-the-difference-between-using-let-and-var-to-declare-a-variable
https://medium.com/javascript-scene/javascript-es6-var-let-or-const-ba58b8dcde75
var has no block scope
var variables are either function-wide or global, they are visible through blocks.
For instance:
|
1 2 3 4 |
if (true) { var test = true; // use "var" instead of "let" } alert(test); // true, the variable lives after if |
If we used let test on the 2nd line, then it wouldn’t be visible to alert. But var ignores code blocks, so we’ve got a global test.
var HAS function scope
|
1 2 3 4 5 6 7 |
function sayHi() { var phrase = "Hello"; // local variable, "var" instead of "let" alert(phrase); // Hello } sayHi(); alert(phrase); // Error, phrase is not defined |
var cannot be block- or loop-local
|
1 2 3 4 |
for(var i = 0; i < 10; i++) { // ... } alert(i); // 10, "i" is visible after loop, it's a global variable |
vars are processed at the function start
var declarations are processed when the function starts (or script starts for globals).
In other words, var variables are defined from the beginning of the function, no matter where the definition is (assuming that the definition is not in the nested function).
So this code:
|
1 2 3 4 5 |
function sayHi() { phrase = "Hello"; alert(phrase); var phrase; } |
is same as:
|
1 2 3 4 5 |
function sayHi() { var phrase; phrase = "Hello"; alert(phrase); } |
..and same as this:
|
1 2 3 4 5 6 7 8 9 |
function sayHi() { phrase = "Hello"; // (*) if (false) { var phrase; } alert(phrase); } |
People also call such behavior “hoisting” (raising), because all var are “hoisted” (raised) to the top of the function.
So in the example above, if (false) branch never executes, but that doesn’t matter. The var inside it is processed in the beginning of the function, so at the moment of (*) the variable exists.
Assignments are not hoisted
|
1 2 3 4 5 6 |
function sayHi() { var phrase; // declaration works at the start... alert(phrase); // undefined phrase = "Hello"; // ...assignment - when the execution reaches it. } sayHi(); |
Because all var declarations are processed at the function start, we can reference them at any place. But variables are undefined until the assignments.
In both examples above alert runs without an error, because the variable phrase exists. But its value is not yet assigned, so it shows undefined.
Let
let allows you to declare variables that are limited in scope to the block, statement, or expression on which it is used. This is unlike the var keyword, which defines a variable globally, or locally to an entire function regardless of block scope. An explanation of why the name “let” was chosen can be found here.
up vote
3526
down vote
accepted
The difference is scoping. var is scoped to the nearest function block and let is scoped to the nearest enclosing block, which can be smaller than a function block. Both are global if outside any block.
Also, variables declared with let are not accessible before they are declared in their enclosing block. As seen in the demo, this will throw a ReferenceError exception.
Block Visibility
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
function allyIlliterate() { //tuce is NOT visible out here for( let tuce = 0; tuce < 5; tuce++ ) { //tuce is only visible in here (and in the for() parentheses) //and there is a separate tuce variable for each iteration of the loop } //tuce is NOT visible out here } function byE40() { //nish *is* visible out here for( var nish = 0; nish < 5; nish++ ) { } //nish *is* visible out here } |
Redeclaration
Assuming strict mode, var will let you re-declare the same variable in the same scope. On the other hand, let will not:
|
1 2 3 4 5 6 7 |
'use strict'; let me = 'foo'; let me = 'bar'; // SyntaxError: Identifier 'me' has already been declared 'use strict'; var me = 'foo'; var me = 'bar'; // No problem, `me` is replaced. |
Global
They are very similar when used like this outside a function block.
|
1 2 3 4 5 6 7 8 9 |
let me = 'go'; // globally scoped var i = 'able'; // globally scoped // However, global variables defined with let will not be added // as properties on the global window object like those // defined with var. console.log(window.me); // undefined console.log(window.i); // 'able' |
More Examples
When using var, and there’s no function enclosed, the variable gets globally scoped. In other words, by definition,
var are function scoped. But since there is no function, it gets globally scoped.
|
1 2 3 4 5 6 7 |
var age = 100; if(age > 12) { var dogYears = age * 7; console.log(`You are ${dogYears} dog years old!`); } // age is valid here |
let is blocked something
Any time you see a curly bracket, its a block. Functions are also blocks. Let and const are still going to be scoped to a function, but if inside of that function or if inside some other element that you have, it will be scoped to the closest set of curly brackets.
|
1 2 3 4 5 6 |
var age = 100; if(age > 12) { let dogYears = age * 7; console.log(`You are ${dogYears} dog years old!`); } console.log(dogYears); // error because it's scoped only to the above block |
const
const is the same as let, the difference lies in that const cannot be reassigned. Let can.
However, keep in mind that properties of const can be reassigned.
const is a signal that the identifier won’t be reassigned.
let is a signal that the variable may be reassigned. i.e counter in a loop, value swap in algorithm.
It also signals that the variable will be used only in the block it’s defined in.
var is now the weakest signal available because it may or may not be reassigned. The variable may
or may not be used for an entire function, or just for the purpose of a block or loop.
Garbage Collection (js)
http://javascript.info/garbage-collection
Reachability
The main concept of memory management in JavaScript is reachability.
Simply put, reachable values are those that are accessible or usable somehow. They are guaranteed to be stored in memory.
There’s a base set of inherently reachable values, that cannot be deleted for obvious reasons.
For instance:
– Local variables and parameters of the current function.
– Variables and parameters for other functions on the current chain of nested calls.
– Global variables. (there are some other, internal ones as well)
– These values are called roots.
Any other value is considered reachable if it’s reachable from a root by a reference or by a chain of references.
For instance, if there’s an object in a local variable, and that object has a property referencing another object, that object is considered reachable. And those that it references are also reachable.
|
1 2 3 4 |
// user has a reference to the object let user = { name: "John" }; |
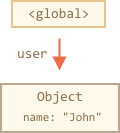
Here the arrow depicts an object reference. The global variable “user” references the object {name: “John”} (we’ll call it John for brevity). The “name” property of John stores a primitive, so it’s painted inside the object.
If the value of user is overwritten, the reference is lost:
|
1 |
user = null; |
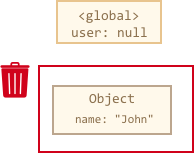
Now John becomes unreachable. There’s no way to access it, no references to it. Garbage collector will junk the data and free the memory.
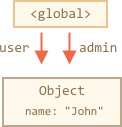
2 references
|
1 2 3 4 5 6 |
// user has a reference to the object let user = { name: "John" }; let admin = user; |
|
1 |
user = null; |
… the object is still reachable via admin global variable, so it’s in memory. If we overwrite admin too, then it can be removed.
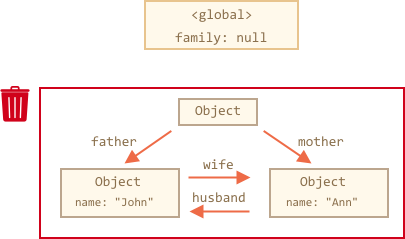
Interlinked objects
Now a more complex example. The family:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
function marry(man, woman) { woman.husband = man; man.wife = woman; return { father: man, mother: woman } } let family = marry({ name: "John" }, { name: "Ann" }); |
First, let’s start from main. We have a family reference that points to the function marry. At this point know that marry‘s function data will all be pushed onto the local stack.
– return reference, not known yet
– param “man” reference, which points to the object with property name “John”
– param “woman” reference, which points to the object with property name “Ann”
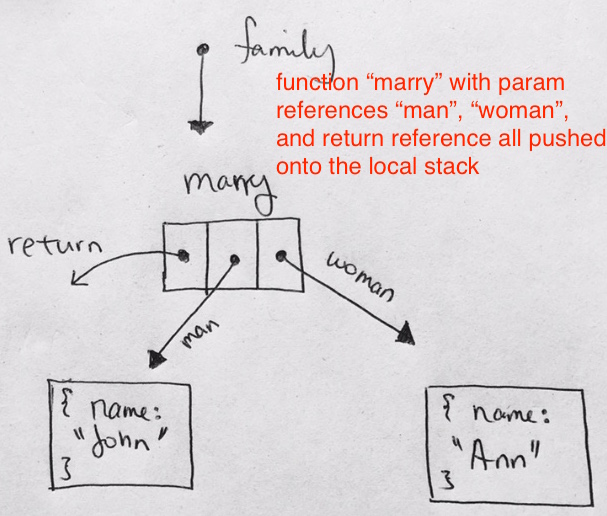
After the code runs through, and just before marry function pops, the snapshot looks like below. The function’s references have not been popped yet, and points to their relative objects:
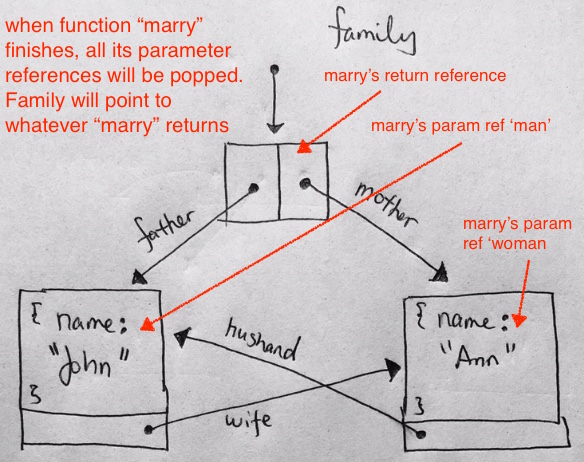
After the marry function pops, all its references will be removed.
Then, let’s say we decide to remove some references:
|
1 2 |
delete family.father; delete family.mother.husband; |
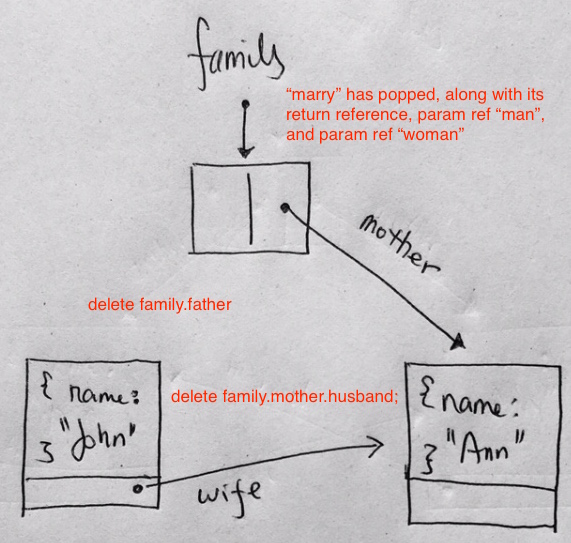
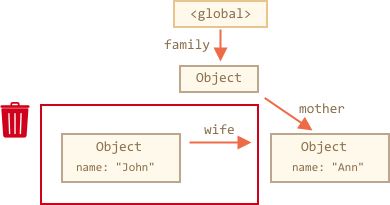
Unreachable island
It is possible that the whole island of interlinked objects becomes unreachable and is removed from the memory.
The source object is the same as above. Then:
|
1 |
family = null; |
The in-memory picture becomes:
The root has unlinked, there’s no reference to it any more, so the whole island becomes unreachable and will be removed.
Internal algorithms
The basic garbage collection algorithm is called mark-and-sweep.
The following “garbage collection” steps are regularly performed:
– The garbage collector takes roots and ‘marks’ (remembers) them.
– Then it visits and “marks” all references from them.
– Then it visits marked objects and marks their references. All visited objects are remembered, so as not to visit the same object twice in the future.
– And so on until there are unvisited references (reachable from the roots).
All objects except marked ones are removed.
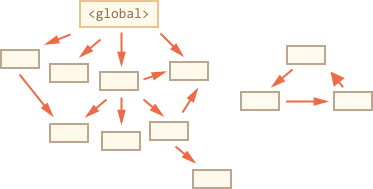
We can clearly see an “unreachable island” to the right side. Now let’s see how “mark-and-sweep” garbage collector deals with it.
The first step marks the roots:
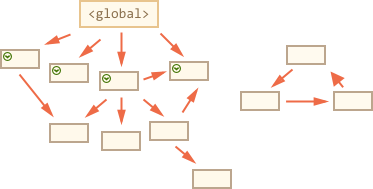
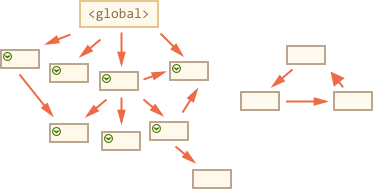
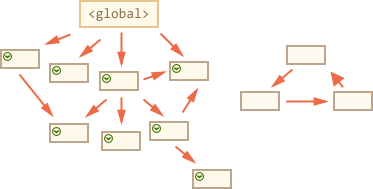
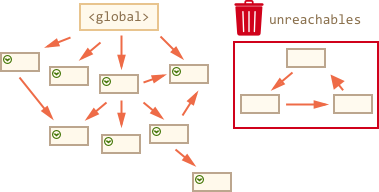
The main things to know:
Garbage collection is performed automatically. We cannot force or prevent it.
Objects are retained in memory while they are reachable.
Being referenced is not the same as being reachable (from a root): a pack of interlinked objects can become unreachable as a whole.
f.prototype and constructor (js)
http://javascript.info/function-prototype
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
function Rabbit() { console.log("Rabbit Constructor"); } console.log(Rabbit.prototype); console.log(Rabbit.prototype.constructor); Rabbit.prototype = { name: "not entered" } console.log(Rabbit.prototype); console.log(Rabbit.prototype.constructor); Rabbit.prototype.copy = function() { // return new Person(this.name); // just as bad return new Rabbit(); }; console.log(Rabbit.prototype); console.log(Rabbit.prototype.constructor); var a = new Rabbit(); console.log(a.__proto__); console.log(a.__proto__.constructor); |
[DRAWING HERE]
In modern JavaScript we can set a prototype using __proto__.
But in the old times, there was another (and the only) way to set it: to use a “prototype” property of the constructor function.
It is known that, when “new F()” creates a new object…
the new object’s [[Prototype]] is set to F.prototype
In other words, if function F has a prototype property with a value of the object type, then the “new” operator uses it to set [[Prototype]] for the new object.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
"use strict" function ParentRabbit() { this.eats = true; this.parentDisplay = function() { console.log("-- ParentRabbit parentDisplay --"); console.log("Does it eat? " + this.eats); } } // function object function Rabbit(newName) { this.rabbitName = newName || "Not Given"; this.display = function() { console.log("-- Rabbit display --"); console.log("name: "+this.rabbitName); } } // F has prototype property with a value to object var animal = new ParentRabbit("White Rabbit"); Rabbit.prototype = animal; // rabbit.__proto__ == animal // the "new" operator uses it to // set [[Prototype]] for the new object let rabbit = new Rabbit(); rabbit.display(); rabbit.parentDisplay(); console.log("accessing parent's property"); console.log(rabbit.eats); |
Setting Rabbit.prototype = animal literally states the following: “When a new Rabbit is created, assign its [[Prototype]] to animal”.

Constructor Property
As stated previous, we have the “prototype” property point to whatever object we want as the parent class to be inherited from future “new”-ed functions.
However, what is this “prototype” property before our assignment?
Every function has the “prototype” property even if we don’t supply it.
The default “prototype” property points to an object with the only property constructor that points back to the function itself.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
"use strict" function Rabbit() { this.rabbitName = "not entered"; this.display = function() { console.log(this.rabbitName); } } // default prototype property console.log(Rabbit.prototype); // Rabbit {} //constructor points back to Function type Rabbit console.log(Rabbit.prototype.constructor); // [Function: Rabbit] function ParentRabbit() { this.rabbitType = "Rare Breed"; this.displayBreed = function() { console.log(this.rabbitType); } } console.log(ParentRabbit.prototype); // Rabbit {} // constructor points to Function type ParentRabbit console.log(ParentRabbit.prototype.constructor); // [Function: ParentRabbit] console.log("sets it to instance of ParentRabbit"); var animal = new ParentRabbit(); Rabbit.prototype = animal; |

You can check it like this:
|
1 |
console.log( Rabbit.prototype.constructor == ParentRabbit ); // true |
Rabbit prototype by default
|
1 2 3 4 5 6 7 8 9 10 11 |
function Rabbit() { this.rabbitName = "not entered"; this.display = function() { console.log(this.rabbitName); } } // default prototype property console.log(Rabbit.prototype); // Rabbit {} console.log(Rabbit.prototype.constructor); // constructor points back to Function type Rabbit |
By default whatever objects created from “new Rabbit()” will inherit from Rabbit.
The instance ‘rabbit’ has constructor property which points to Rabbit.

We can use constructor property to create a new object using the same constructor as the existing one.
Like here:
|
1 2 3 4 5 6 7 |
function Rabbit(name) { this.name = name; alert(name); } let rabbit = new Rabbit("White Rabbit"); let rabbit2 = new rabbit.constructor("Black Rabbit"); |
Future manipulations of the prototype property
JavaScript itself does not ensure the right “constructor” value.
Yes, it exists in the default object that property prototype references, but that’s all. What happens with it later – is totally on us.
In this example, we see that we repointed the prototype to a totally different object. Thus, other instances of Rabbit, will be deriving from the object with property jumps: true.
The assumption that instances of Rabbit will have a ‘Rabbit’ constructor will then be false.
|
1 2 3 4 5 6 7 |
function Rabbit() {} Rabbit.prototype = { jumps: true }; let rabbit = new Rabbit(); alert(rabbit.constructor === Rabbit); // false |
So, to keep the right “constructor” we can choose to add/remove properties to the default “prototype” instead of overwriting it as a whole:
|
1 2 3 4 5 6 |
function Rabbit() {} // Not overwrite Rabbit.prototype totally // just add to it Rabbit.prototype.jumps = true // the default Rabbit.prototype.constructor is preserved |
Or you can reconstruct it yourself. Just make sure to include the constructor property and set it to your this object:
|
1 2 3 4 |
Rabbit.prototype = { jumps: true, constructor: Rabbit }; |
The only thing F.prototype does: it sets [[Prototype]] of new objects when “new F()” is called.
The value of F.prototype should be either an object or null: other values won’t work.
The “prototype” property only has such a special effect when is set to a constructor function, and invoked with new.
|
1 2 3 4 |
let user = { name: "John", prototype: "Bla-bla" // no magic at all }; |
By default all functions have F.prototype = { constructor: F }, so we can get the constructor of an object by accessing its “constructor” property.
Gotchas
|
1 2 3 4 5 6 7 8 9 10 |
function Rabbit() {} Rabbit.prototype = { eats: true }; let rabbit = new Rabbit(); // rabbit's __proto__ is now set to Rabbit Rabbit.prototype = {}; console.log( rabbit.eats ); // true |
The assignment to Rabbit.prototype sets up [[Prototype]] for new objects. The new object ‘rabbit’ then points to Rabbit. The instance rabbit’s [[Prototype]] then is pointing to Rabbit’s default prototype object with its constructor property.
Then Rabbit’s prototype points to an empty object. However, rabbit’s [[Prototype]] already is referencing Rabbit’s default prototype object with its constructor property. Hence that’s why rabbit.eats is true.
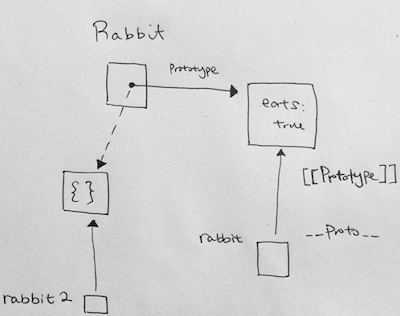
Problem 1
|
1 2 3 4 5 6 7 8 9 10 |
function Rabbit() {} Rabbit.prototype = { eats: true }; let rabbit = new Rabbit(); Rabbit.prototype = {}; alert( rabbit.eats ); // ? |
solution: true
Problem 2
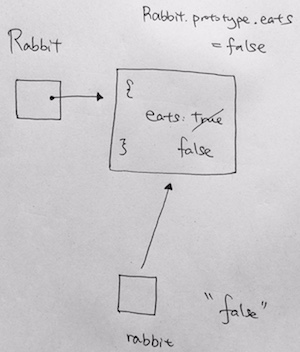
|
1 2 3 4 5 6 7 8 9 10 |
function Rabbit() {} Rabbit.prototype = { eats: true }; let rabbit = new Rabbit(); Rabbit.prototype.eats = false; alert( rabbit.eats ); // ? |
Solution: false
Problem 3
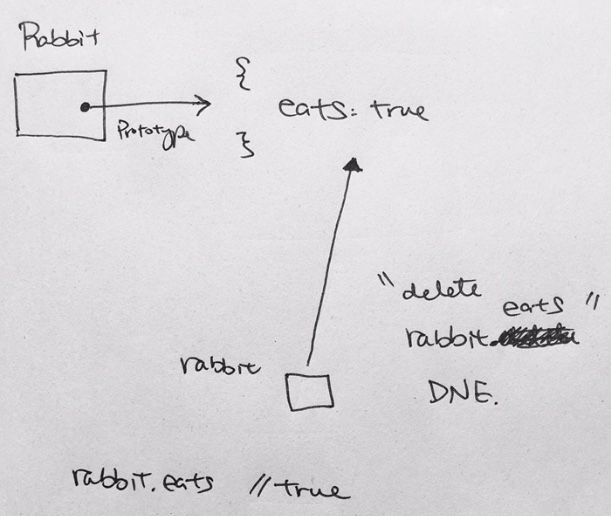
|
1 2 3 4 5 6 7 8 9 10 |
function Rabbit() {} Rabbit.prototype = { eats: true }; let rabbit = new Rabbit(); delete rabbit.eats; alert( rabbit.eats ); // ? |
Solution:
All delete operations are applied directly to the object. Here delete rabbit.eats tries to remove eats property from rabbit, but it doesn’t have it. So the operation won’t have any effect.
Problem 4
|
1 2 3 4 5 6 7 8 9 10 |
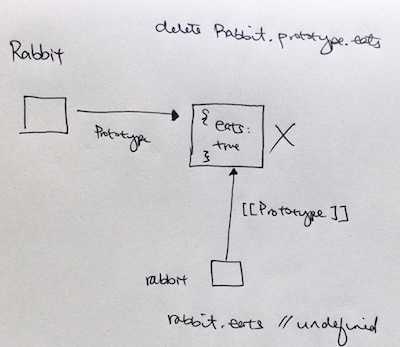
function Rabbit() {} Rabbit.prototype = { eats: true }; let rabbit = new Rabbit(); delete Rabbit.prototype.eats; alert( rabbit.eats ); // ? |
Solution
Constructors (js)
https://javascript.info/constructor-new
The purpose of constructors is to implement reusable object creation code
Constructor functions technically are regular functions. There are two conventions though:
They are named with capital letter first.
They should be executed only with “new” operator.
Every function is an object, and when an object is created with “new”, it runs through the constructor.
1) The constructor then uses ‘this’ and assigns an empty object to it.
2) It will then add properties you specify onto “this”.
3) Finally, it returns this.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
function User(name) { // this = {}; (implicitly) // add properties to this this.name = name; this.isAdmin = false; // return this; (implicitly) } let user = new User('Ricky'); console.log(user.name); // Ricky console.log(user.isAdmin); // false |
Constructors in Javascript is used to construct objects and can be called many times by any references.
However, constructors can also be created and called just once, and not be saved for later use.
|
1 2 3 4 5 6 7 8 9 10 11 |
let john = new function() { this.name = 'John'; this.isAdmin = false; // ...other code for user creation // maybe complex logic and statements // local variables etc }; console.log(john.name); // John console.log(john.isAdmin); // false |
DUAL SYNTAX: new.target
ref – http://chineseruleof8.com/code/index.php/2016/02/29/this-in-function/
Inside a function, we can check whether it was called with new or without it, using a special new.target property.
This can be used to allow both new and regular syntax to work the same. The reason why we care about “new” is because when we “new” a function, it creates an object out of it with its own “this”.
However, if we do not use “new”, the value of this becomes the global object.
In a web browser the global object is the browser window.
For example:
|
1 2 3 4 5 6 7 8 |
var Person = function(name) { this.name = name || 'johndoe'; // 'this' refers to the window object }; var cody = Person('Cody Lindley'); //console.log(cody.name); // UNDEFINED! console.log(window.name); //logs Cody Lindley, |
The reason why window.name logs Cody Lindley is because the ‘this’ inside the function references the window global object. Hence when we attach the attribute name to this, it attaches name to the window object. the ‘this’ has nothing to do with the object Person.
Now, when we use new Object, we create an object on the heap, and “this” in our function refers to that object. IT IS NOT connected to the (global or window) object.
Hence, when we log cody.name, it works because cody is that object in the heap. The this in the function, refers to cody.
In order to make sure the “new” is always applied so that we get some consistency, we can check for new.target to see if “new” was used to create the object. If not, then we need to force it by returning an object using new.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
function Node() { // this = {} // With new we all know that the new object is being created, that’s a good thing. if (!new.target) { console.log('You didnt use new. Giving you a new Node Object'); return new Node(); } // add properties to this this.data = 'NA'; this.next = null; // return this } let head = Node(); console.log(head.data); // NA console.log(head.next); // null |
Return from Constructors
Usually, constructors do not have a return statement. Their task is to write all necessary stuff into this, and it automatically becomes the result.
But if there is a return statement, then the rule is simple:
If return is called with object, then it is returned instead of this.
If return is called with a primitive, it’s ignored.
In other words, return with an object returns that object, in all other cases this is returned.
|
1 2 3 4 5 6 |
function BigUser() { this.name = 'john'; return {species: 'species', name: 'Godzilla'}; // returns is called with object } console.log(new BigUser().name); // Godzilla |
|
1 2 3 4 5 |
function SmallUser() { this.name = 'John'; return; // returns this } console.log(new SmallUser().name); // John |
Methods in Constructor
Having a method in a constructor means you add the method definition as a property to “this”. Once that happens,
after you construct an object, you are free to call that method.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
function ListNode(newData, newNext) { // this = {} // assign properties to self this.data = newData; this.next = newNext; this.display = function() { console.log('display data and next here'); }; // return this } let ListHead = new ListNode('hadoken', null); ListHead.display(); // display data and next here |
Is it possible to create functions A and B such as new A()==new B()?
|
1 2 3 4 5 6 7 |
function A() { ... } function B() { ... } let a = new A; let b = new B; alert( a == b ); // true |
Yes, it’s possible.
If a function returns an object, then new returns it instead of this.
So thay can, for instance, return the same externally defined object obj:
|
1 2 3 4 5 6 |
let obj = {}; function A() { return obj; } function B() { return obj; } alert( new A() == new B() ); // true |
null vs undefined (js)
https://stackoverflow.com/questions/801032/why-is-null-an-object-and-whats-the-difference-between-null-and-undefined
The difference between null and undefined is as follows:
undefined
undefined: used by JavaScript and means “no value”.
– Uninitialized variables
– missing parameters
– unknown variables have that value.
> var noValueYet;
> console.log(noValueYet);
undefined
> function foo(x) { console.log(x) }
> foo()
undefined
> var obj = {};
> console.log(obj.unknownProperty)
undefined
null
null: used by programmers to indicate “no value”, e.g. as a parameter to a function.
Examining a variable:
console.log(typeof unknownVariable === “undefined”); // true
var foo;
console.log(typeof foo === “undefined”); // true
console.log(foo === undefined); // true
var bar = null;
console.log(bar === null); // true
Javascript memory allocation
https://stackoverflow.com/questions/2800463/how-variables-are-allocated-memory-in-javascript
https://stackoverflow.com/questions/1026495/does-javascript-have-a-memory-heap
When you call a function, amongst other things a variable environment for that call is created, which has something called a “variable object”.
The “variable object” has properties for the
– arguments to the function
– all local variables declared in the function
– and all functions declared within the function (along with a couple of other things)
When a closure survives the function returning (which can happen for several reasons), the variable object for that function call is retained in memory (heap) by the reference from the closure.
At first glance, that would suggest that the stack isn’t used for local variables; in fact, modern JavaScript engines are quite smart, and may (if it’s worthwhile) use the stack for locals that aren’t actually used by the closure. (Naturally, the stack is still used for keeping track of return addresses and such.)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
function foo(a, b) { var c; // property c console.log("a: " + a) console.log("b: " + b) c = a + b; console.log("c: " + c) // closure function bar(d) { // can access foo's property c console.log("d * c = " + (d * c)); } return bar; } var b = foo(1, 2); b(3); // logs "d * c = 9" |
Due to our function bar (which is a closure) uses and references c, if our function call ends and pops, our closure bar is still chained to “foo”, and thus be able to use c. Depending on the js engine, it may then move “c”
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
+----------------------------+ | `foo` call variable object | | -------------------------- | | a = 1 | | b = 2 | | c = 3 | | bar = (function) | +----------------------------+ ^ | chain | +----------------------------+ | `bar` call variable object | | -------------------------- | | d = 3 | +----------------------------+ |
Javascript pass by reference or pass by value
https://stackoverflow.com/questions/518000/is-javascript-a-pass-by-reference-or-pass-by-value-language?rq=1
Javascript parameters are pass by value, the value is that of the reference address.
|
1 2 3 4 5 6 7 8 9 |
function changeStuff(numParam) { numParam.item = "changed"; // dereferences } var obj1 = {item: "unchanged"}; // object with item as property changeStuff(obj1); console.log(obj1.item); |
obj1 is a reference that points to the object. Specifically, it points to the address of the object.
In the function changeStuff, its parameter ‘numParam’ is pushed as a reference on to the local function stack. It then copies by value the address of the object pointed to by obj1.
Parameter reference dereferences the object
Inside changeStuff, when we access the property item, our reference would dereference the object and get the value of item. Then assign it a new value “changed”. That’s why when the function finishes and pops, our obj1 reference outside will see that its property item was dereferenced and changed to “changed”.
|
1 |
numParam.item = "changed"; // dereferences |
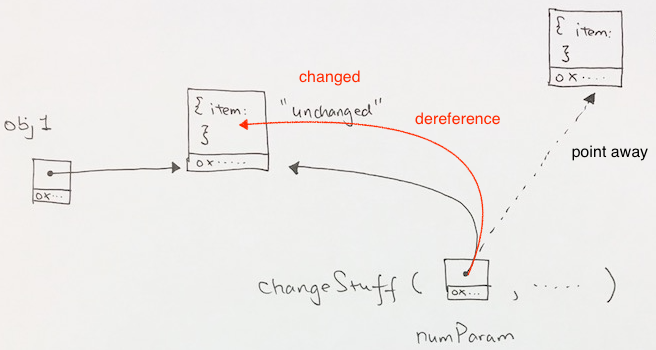
Simply points away
The other situation is that we assign our parameter reference to another object. When this happens, we point our reference away from the object that obj1 points to, and onto the new object. That’s why when our function exits, the obj1 still points to its own object and the item property is still “unchanged”
|
1 2 3 4 5 6 7 8 9 |
function changeStuff(numParam) { numParam = {item: "changed"}; // points away } var obj1 = {item: "unchanged"}; // object with item as property changeStuff(obj1); console.log(obj1.item); |
Primitives – Pass by Value
In JavaScript there are 5 primitive types: undefined , null , boolean , string and number. They are all passed by value.
|
1 2 3 4 5 6 7 8 |
function changeStuff(a) { a = 88; } var num = 10; changeStuff(num); console.log(num); // 10 |
Typing in javascript
https://stackoverflow.com/questions/964910/is-javascript-an-untyped-language
strong/weak can be thought of in relation to how the compiler, if applicable, handles typing.
Weakly typed means the compiler, if applicable, doesn’t enforce correct typing. Without implicit compiler interjection, the instruction will error during run-time.
“12345” * 1 === 12345 // string * number => number
Strongly typed means there is a compiler, and it wants you an explicit cast from string to integer.
(int) “12345” * 1 === 12345
In either case, some compiler’s features can implicitly alter the instruction during compile-time to do conversions for you, if it can determine that is the right thing to do.
Thus far, JavaScript can be categorized as Not-Strongly-Typed. That either means it’s weakly-typed or un-typed.