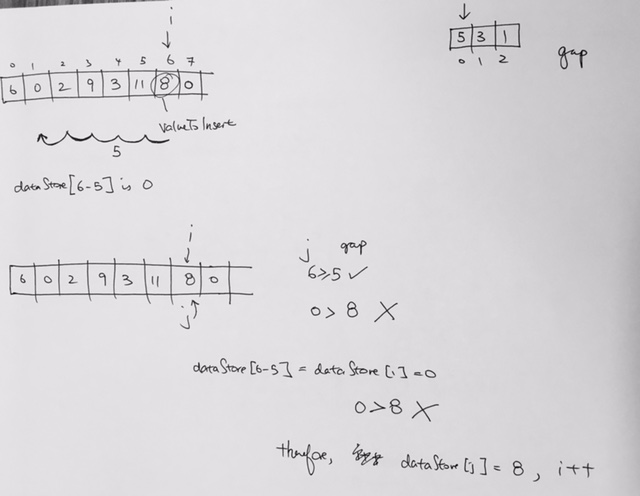
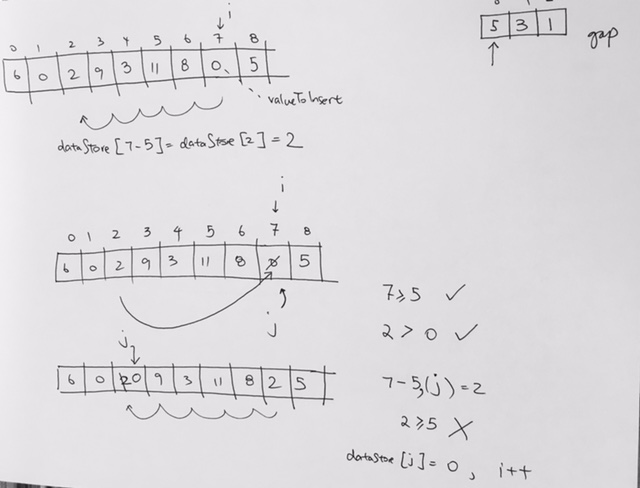
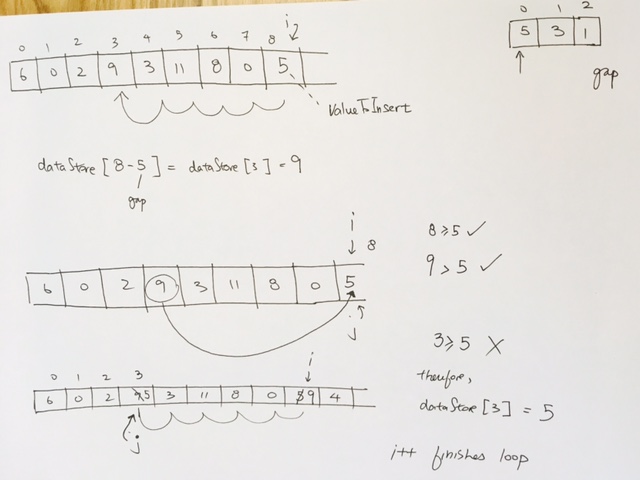
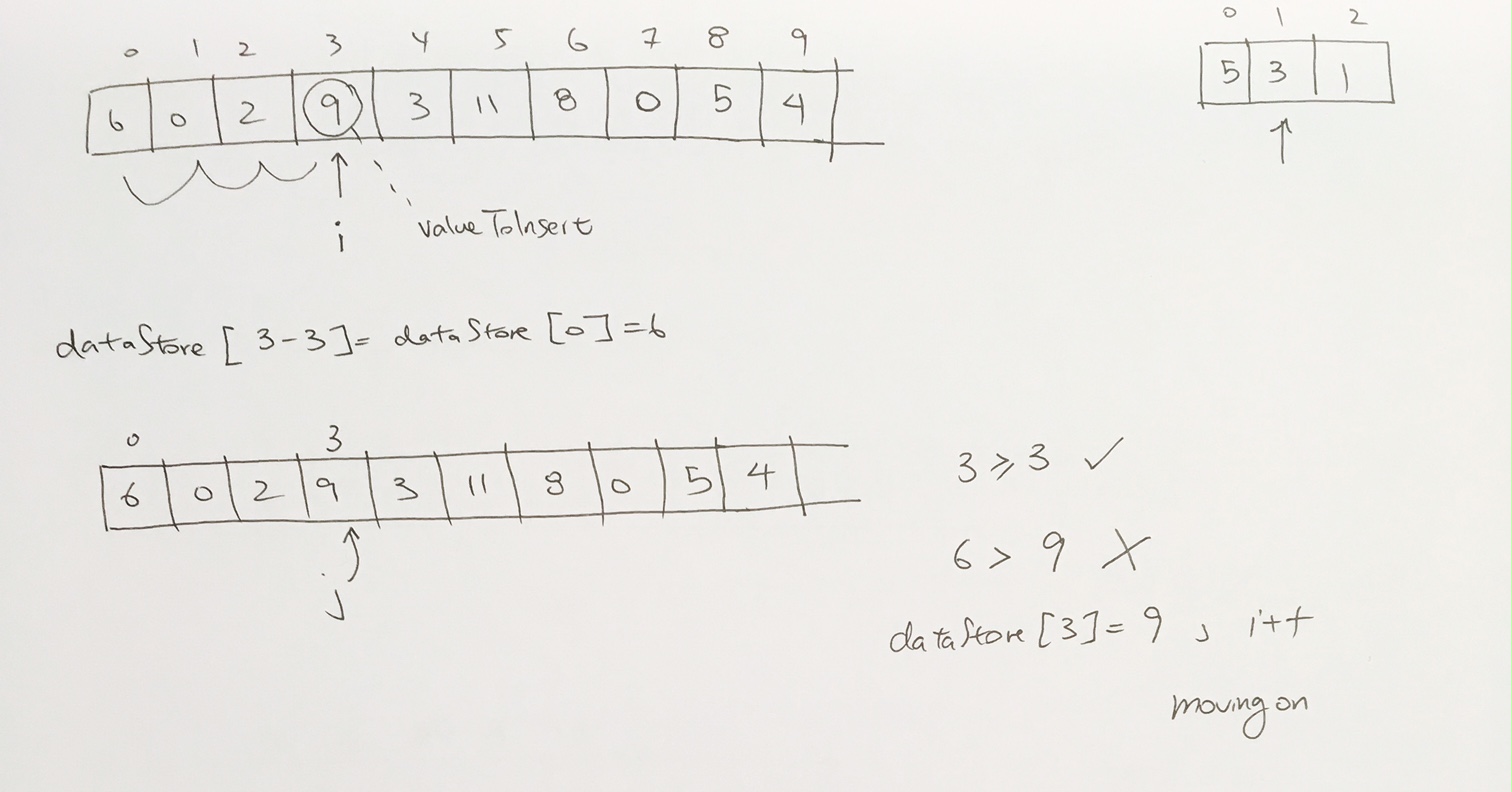
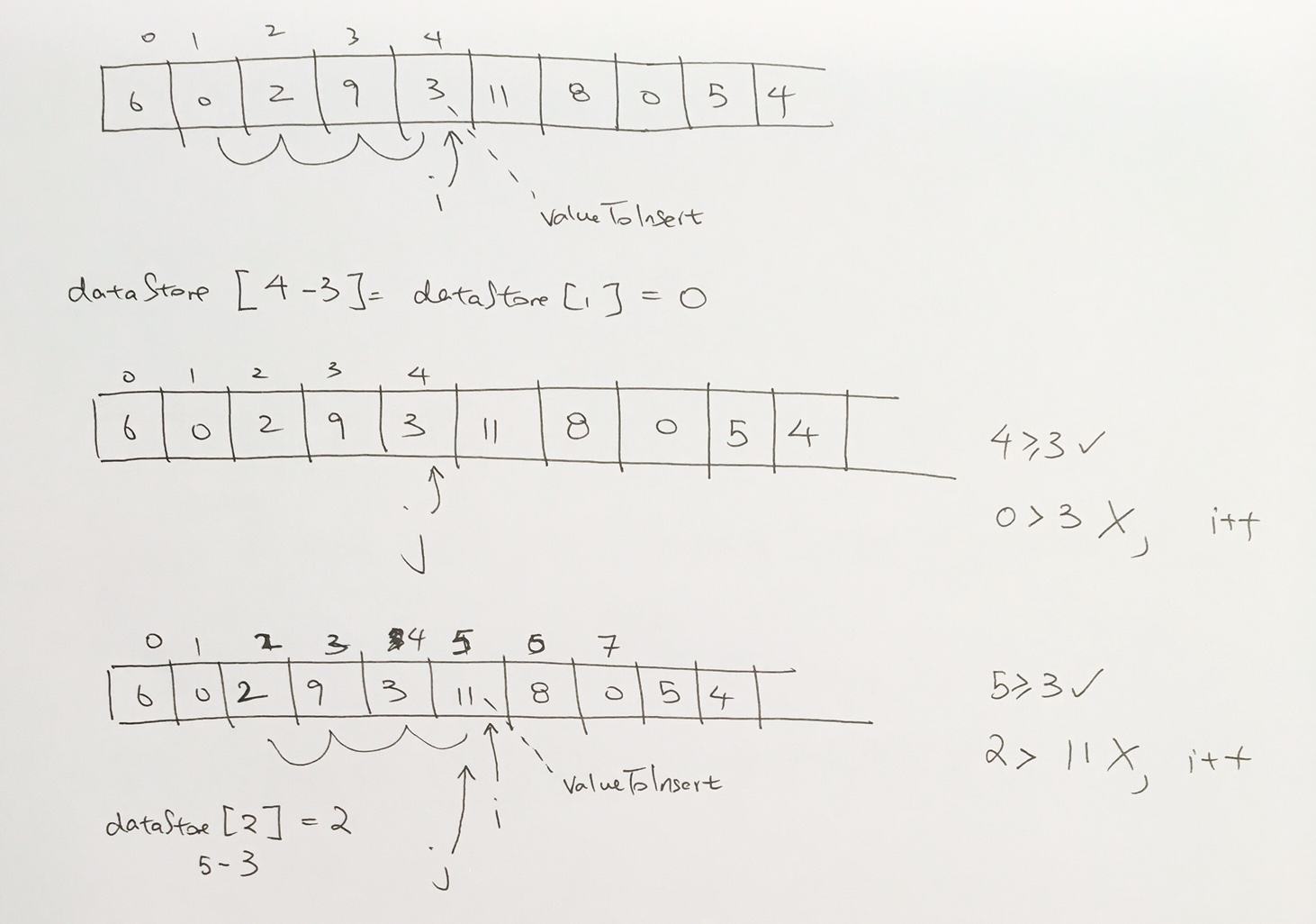
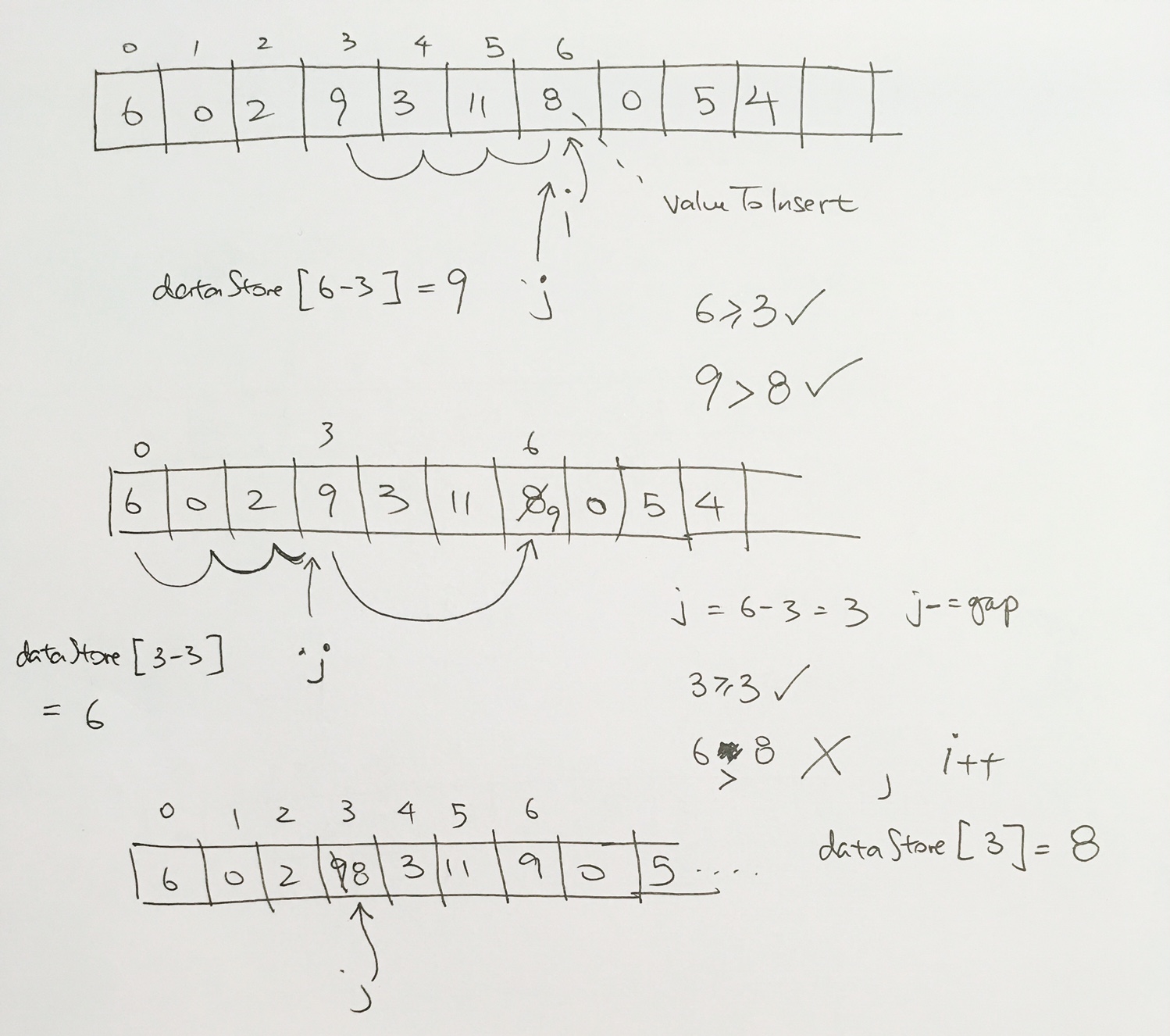
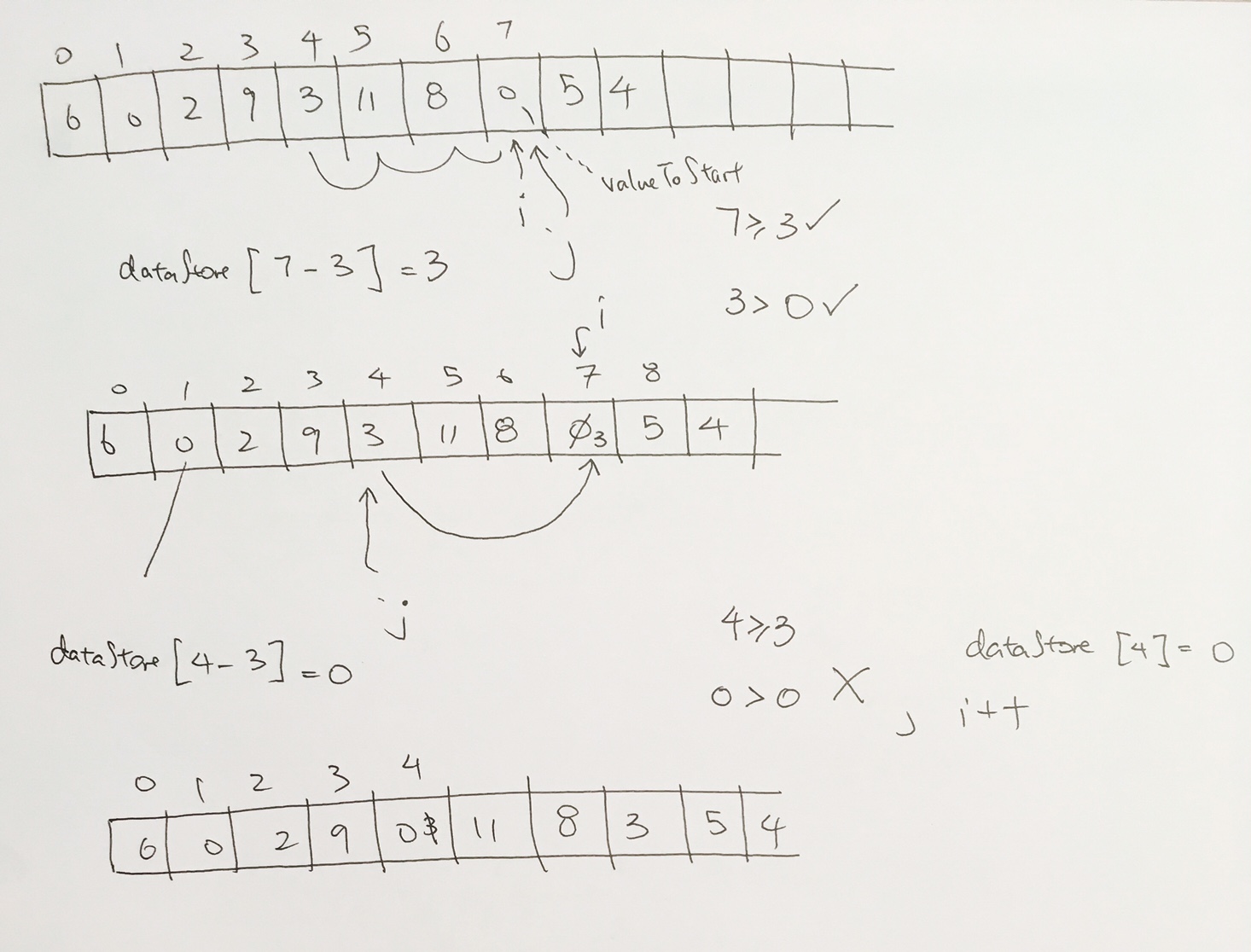
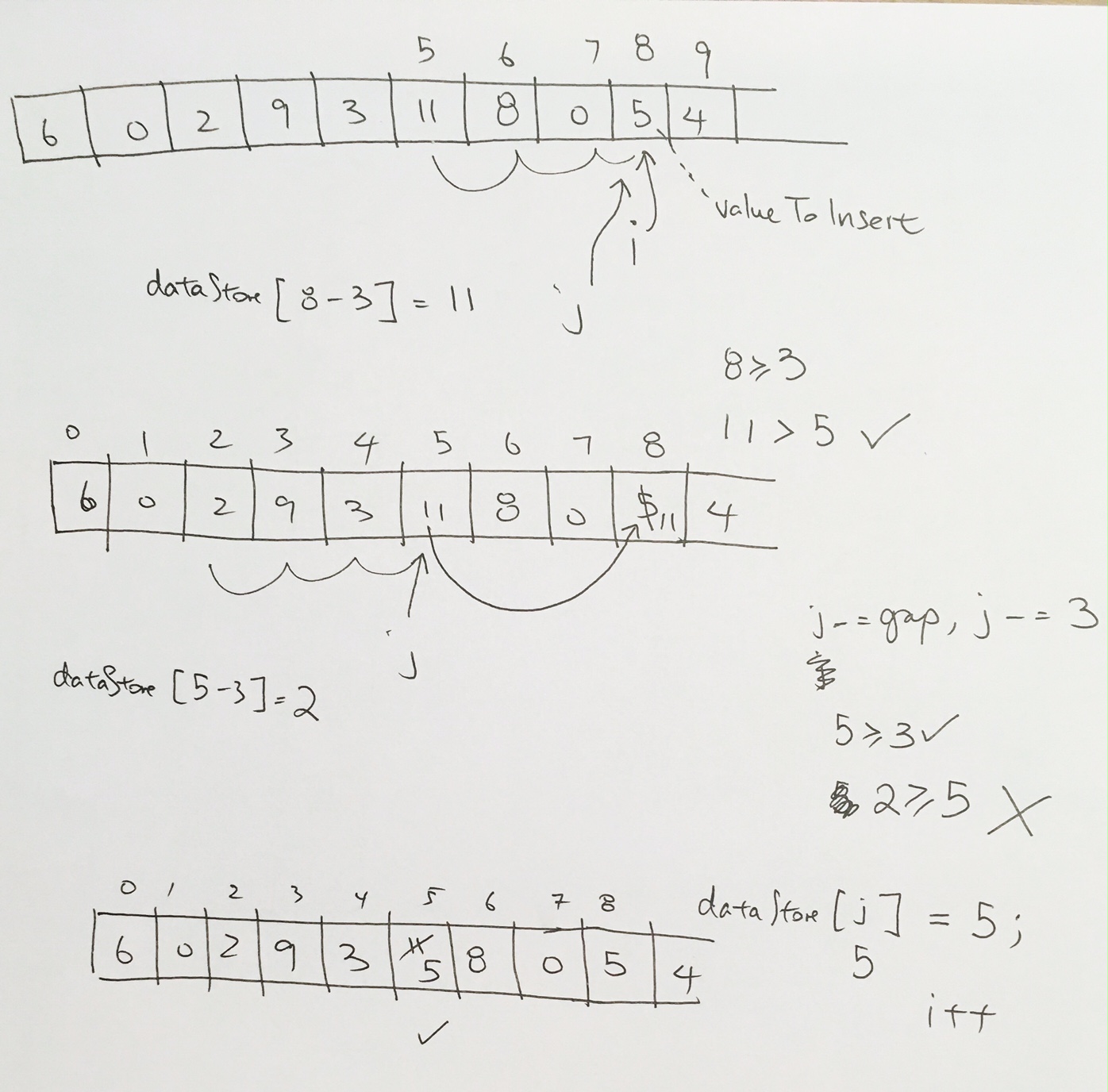
ref –
- https://www.geeksforgeeks.org/travelling-salesman-problem-set-2-approximate-using-mst/
- https://iq.opengenus.org/graph-representation-adjacency-matrix-adjacency-list/
- https://www.gatevidyalay.com/prims-algorithm-prim-algorithm-example/
- source – https://github.com/redmacdev1988/PrimsAlgorithm
- https://www.tutorialspoint.com/Prim-s-algorithm-in-Javascript
What it solves:
Traveling Salesman Problem (Approximate using Minimum Spanning Tree)
Algorithm:
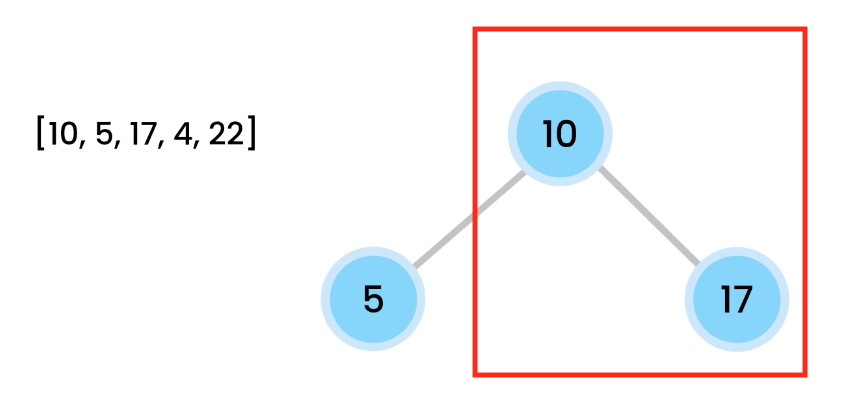
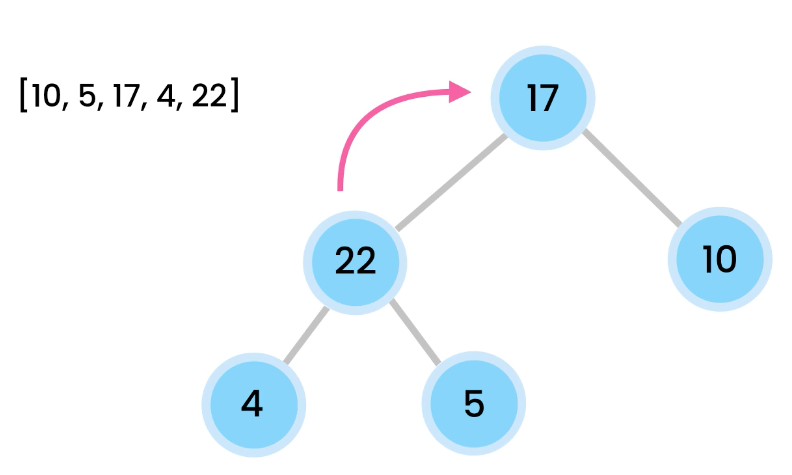
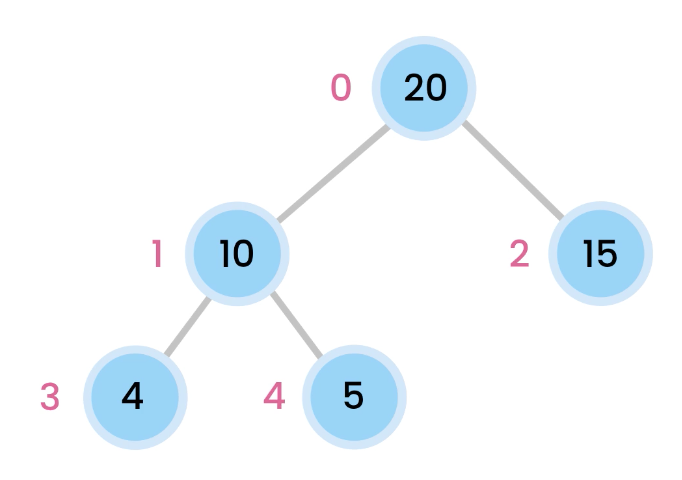
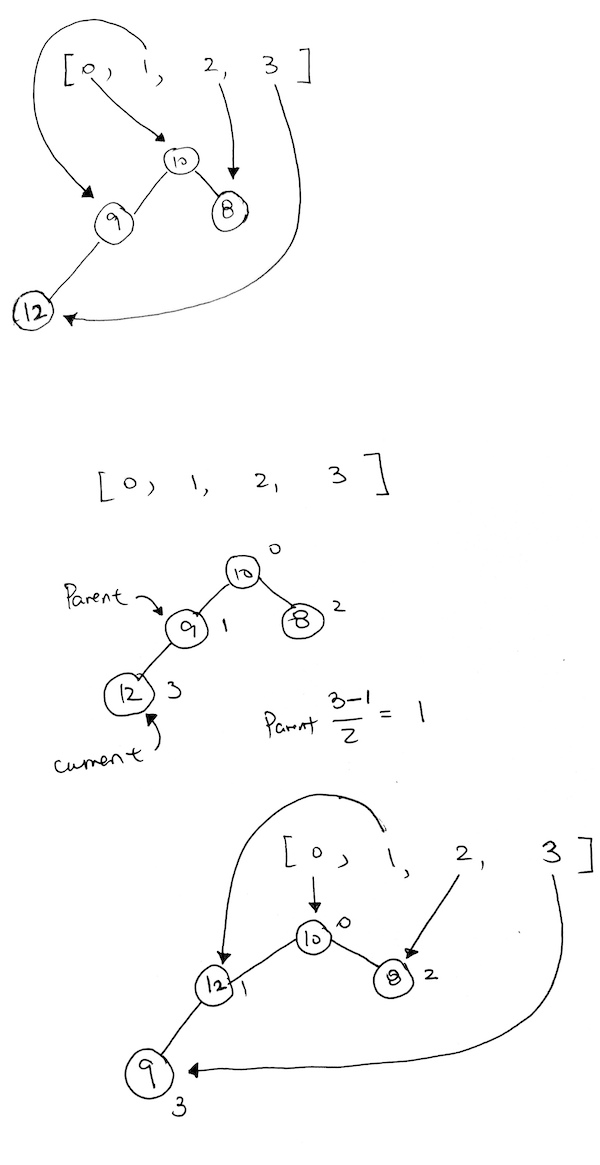
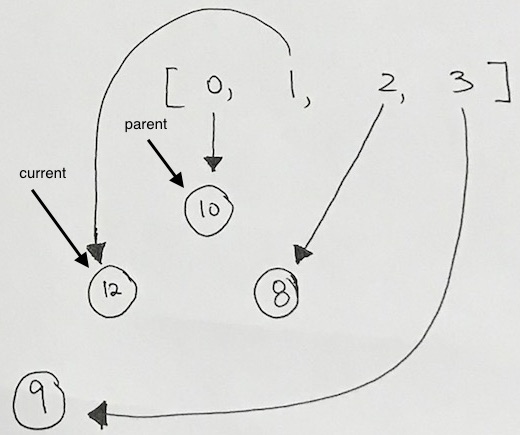
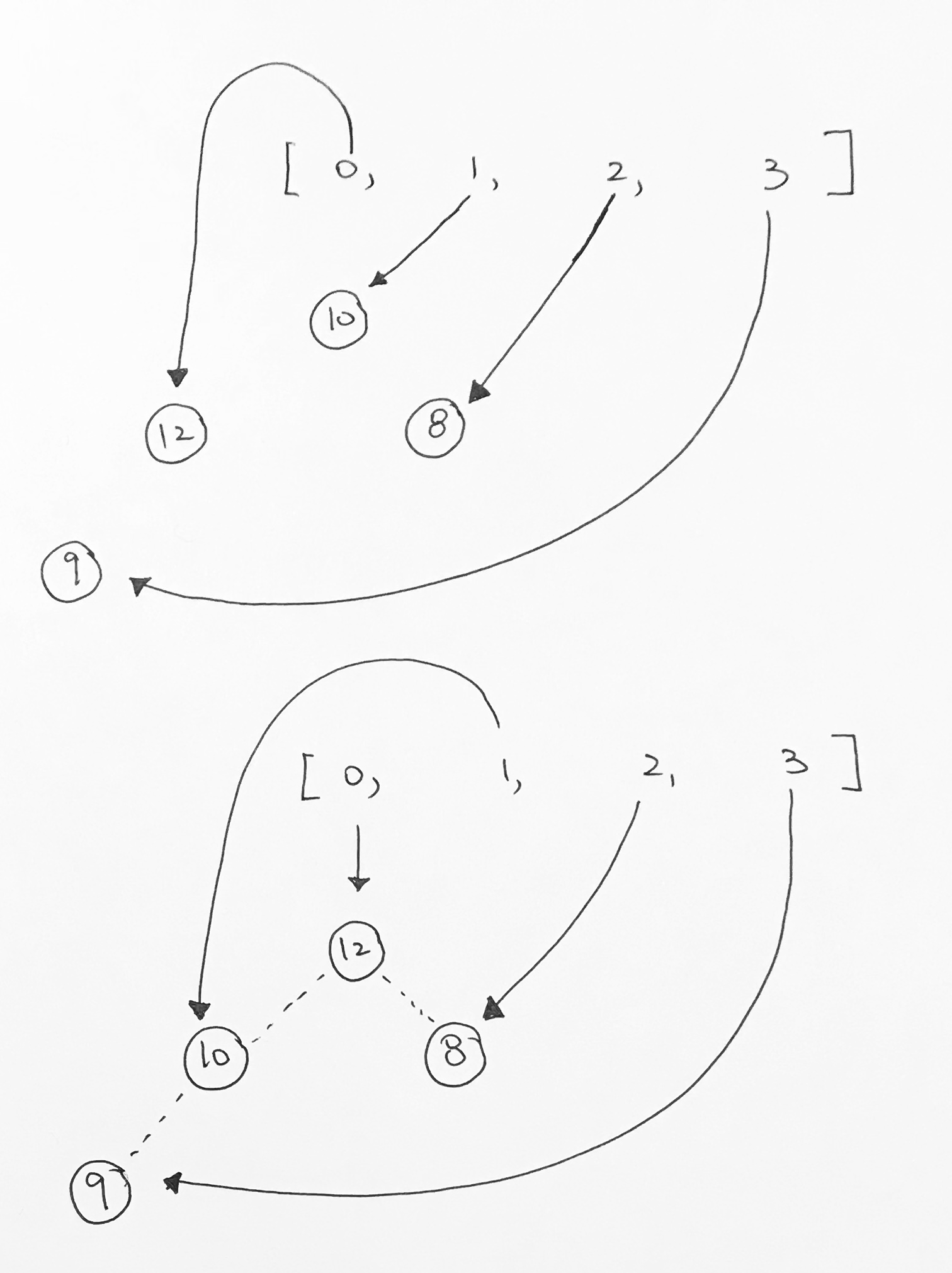
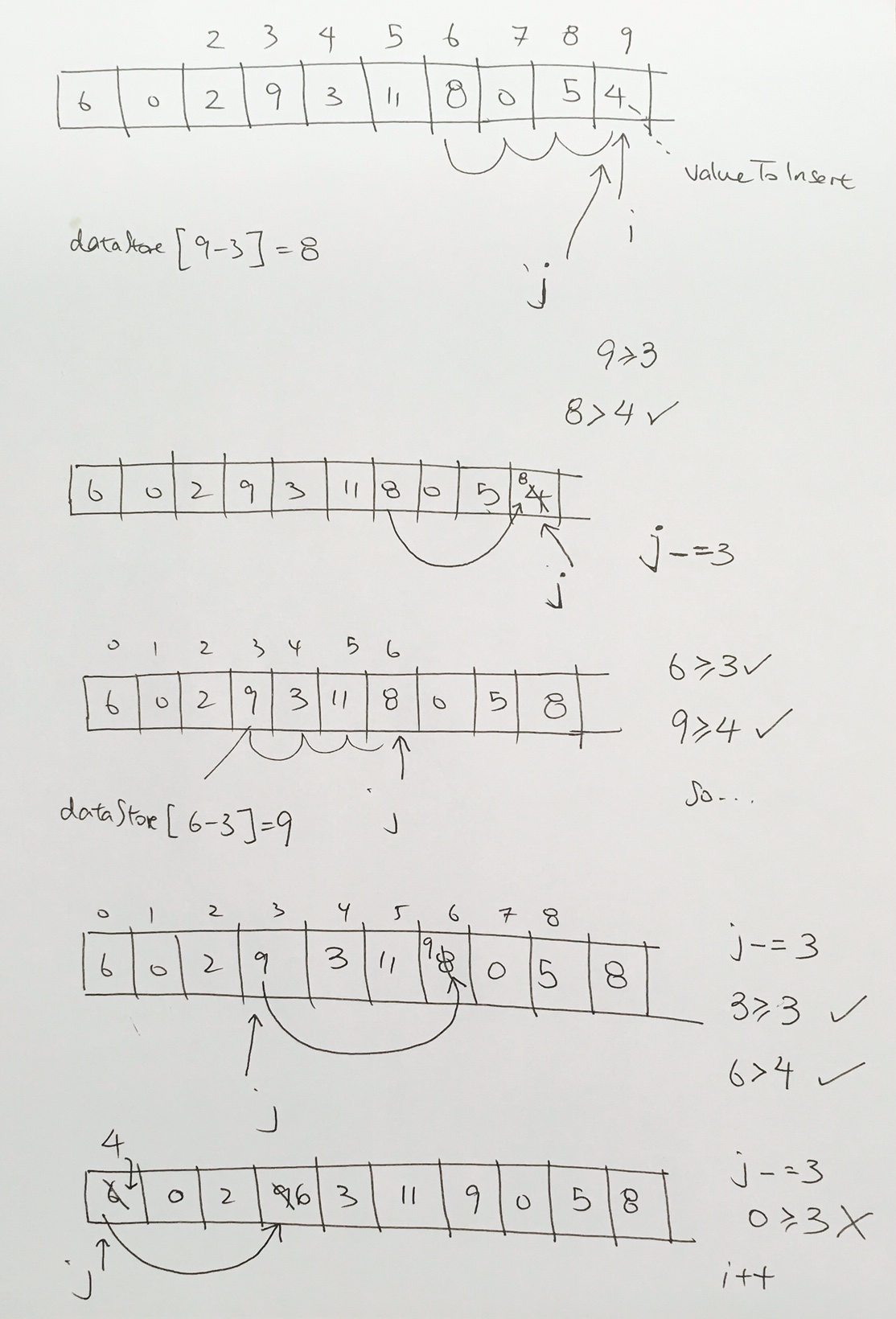
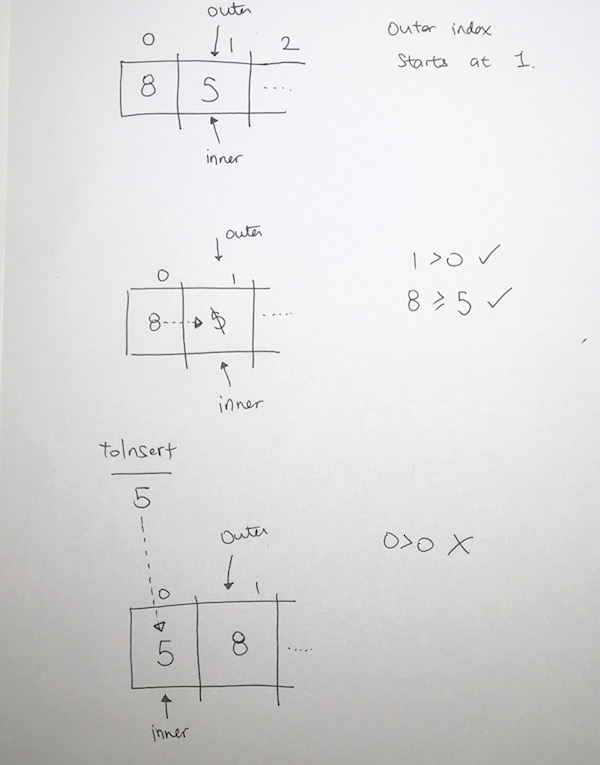
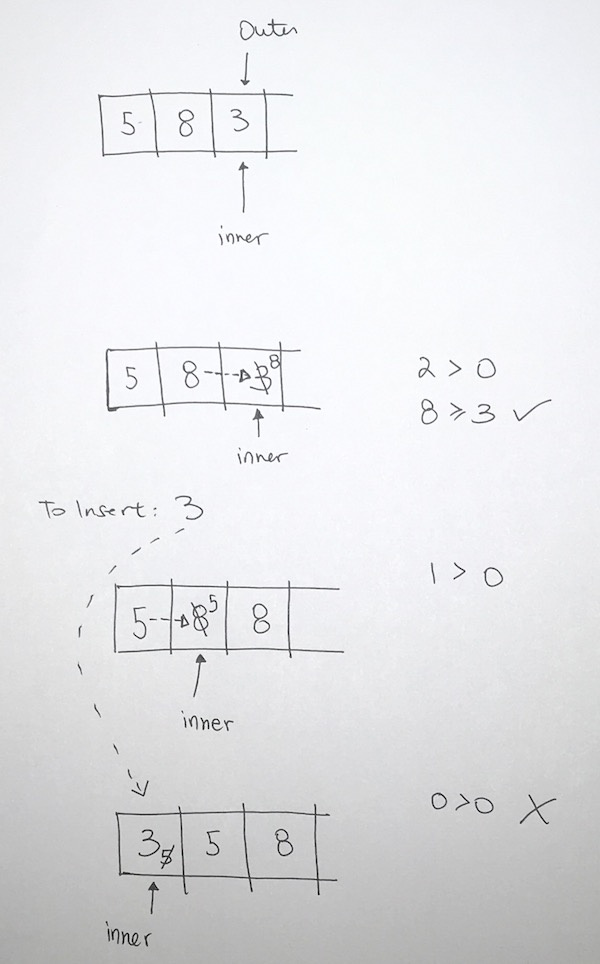
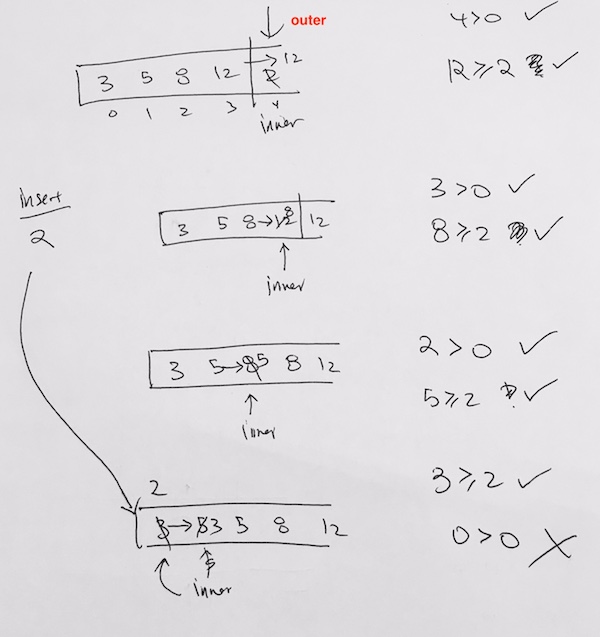
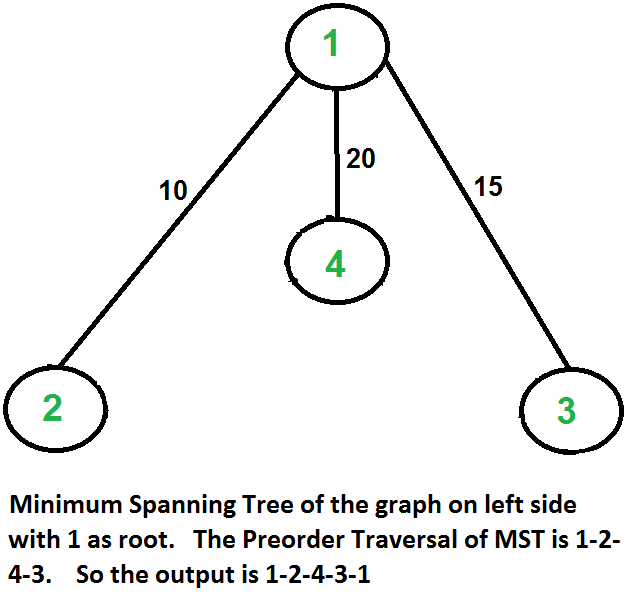
1) Let 1 be the starting and ending point for salesman.
2) Construct MST from with 1 as root using Prim’s Algorithm.
3) List vertices visited in preorder walk of the constructed MST, and add 1 at the end.
Let us consider the following example. The first diagram is the given graph. The second diagram shows MST constructed with 1 as root. The preorder traversal of MST is 1-2-4-3. Adding 1 at the end gives 1-2-4-3-1 which is the output of this algorithm.
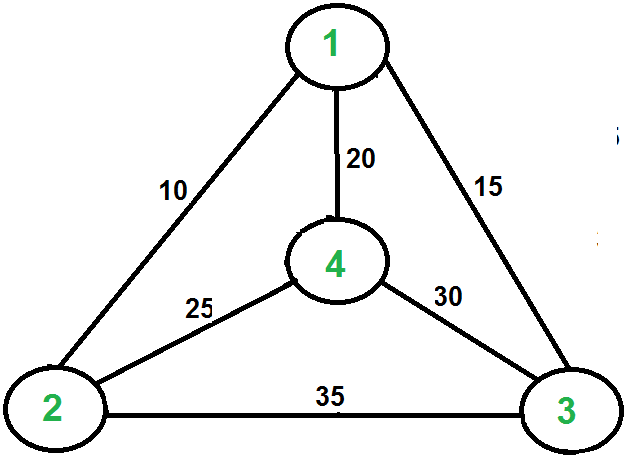
Given a problem like so, we use Prim’s algorithm to create a minimum spanning tree for a weighted undirected graph. It finds a subset of the edges that forms a tree, where the total weight of all the edges in the tree is minimized.
What is Minimum Spanning Tree?
Given a connected and undirected graph, a spanning tree of that graph is a subgraph that is a tree and connects all the vertices together. A single graph can have many different spanning trees. A minimum spanning tree (MST) or minimum weight spanning tree for a weighted, connected and undirected graph is a spanning tree with weight less than or equal to the weight of every other spanning tree. The weight of a spanning tree is the sum of weights given to each edge of the spanning tree.
Prim’s Algorithm
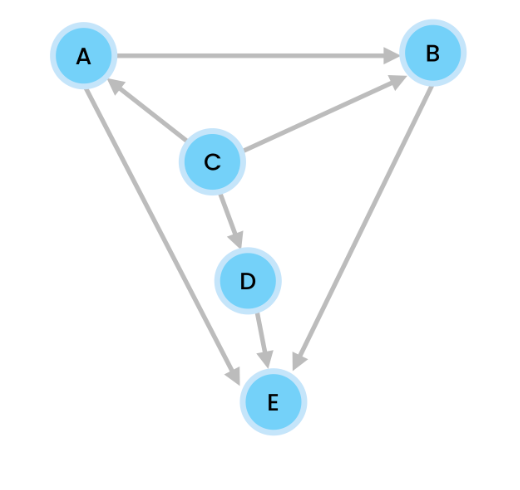
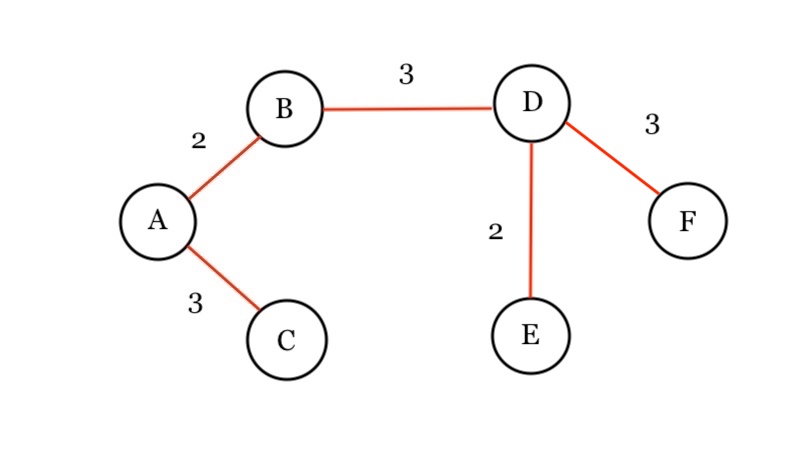
Given Problem
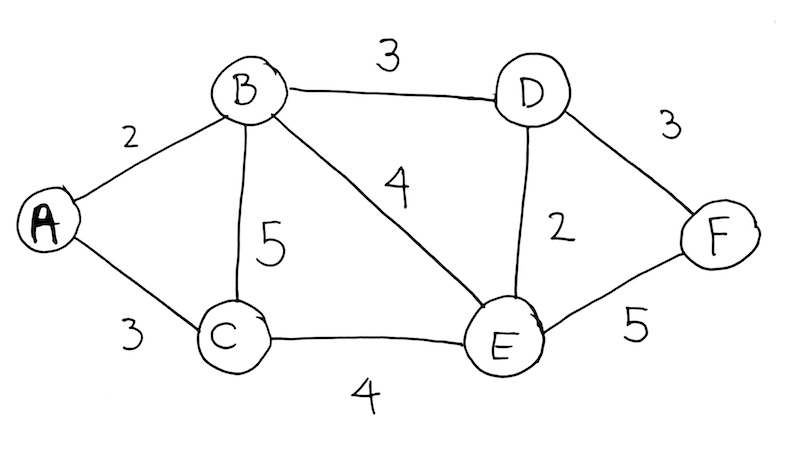
Adjacency List
We create an adjacency list. From the diagram, we see that A connects to B and C. So we create key A, and then have it reference a Linked List with nodes B and C.
We see B connects to C, E, and D. So in our adjacency list, we add key B, and have it reference a Linked List with nodes C, E, and D. Repeat until all edges and vertices have been added.
A -> [B] -> [C]
B -> [A] -> [C] -> [E] -> [D]
C -> [A] -> [B] -> [E]
D -> [B] -> [E] -> [F]
E -> [D] -> [E]
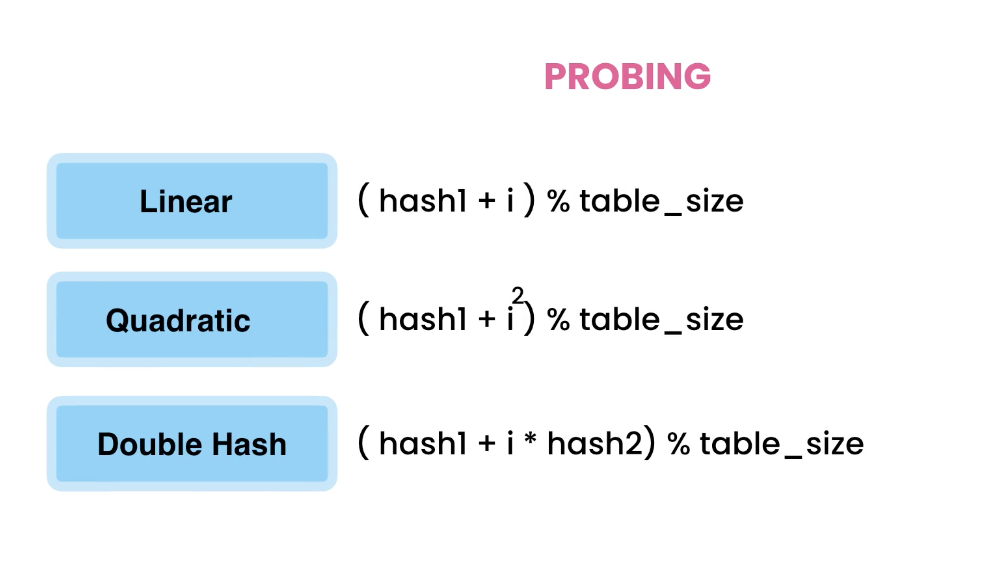
The key to picking only the minimum path and getting rid of the rest is accomplished by:
- minimum priority queue
- visited dictionary to keep track of all visited nodes
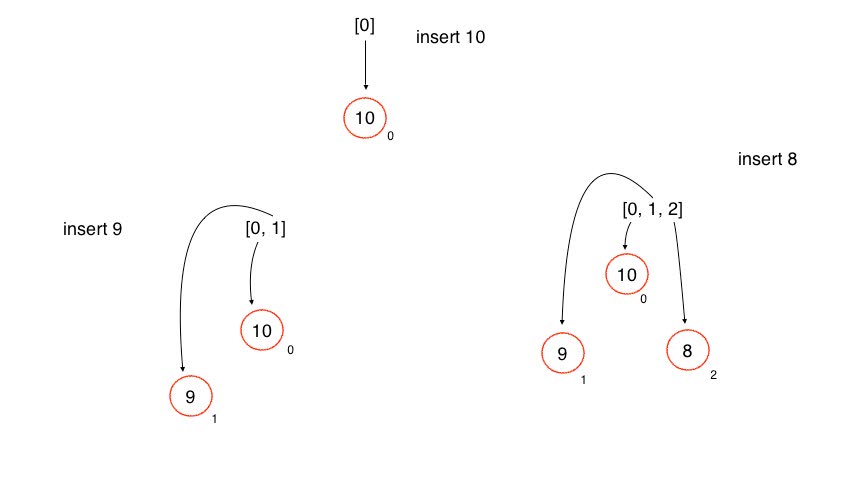
The Minimum Queue
We use the minimum priority queue to keep all the edges from nodes that we have visited. We group these edges into this queue, then take the minimum of it. That is how this algorithm picks the minimum path to travel.
Start
We start at node A so we draw it.
We need to process this node A in our min priority queue so we should add it to initialize our queue.
Min Queue: [A]
Visited: {}
Now that the queue has an item, we can start off the process it.
We pop A from the queue to process it.
Min Queue: []
Visited: {}
Has it been visited? No, so we put it in Visited dictionary.
We see from the adjacency list that A connects to B (with distance of 2) and C (with distance of 3).
So we push B and C into our queue.
Min Queue: [ B(A, 2), C(A, 3) ]
Visited: { “A” }
This means that all edges from A is only B and C. And from this group of edges, we use the min priority queue to get the absolute minimum path (which is 2) at node B.
Hence pop B from the queue.
Min Queue: [ C(A, 3) ]
Visited: { “A” }
Has B been visited? We look at the Visited dictionary. No. So we then add B to the visited dictionary. . We draw our result:
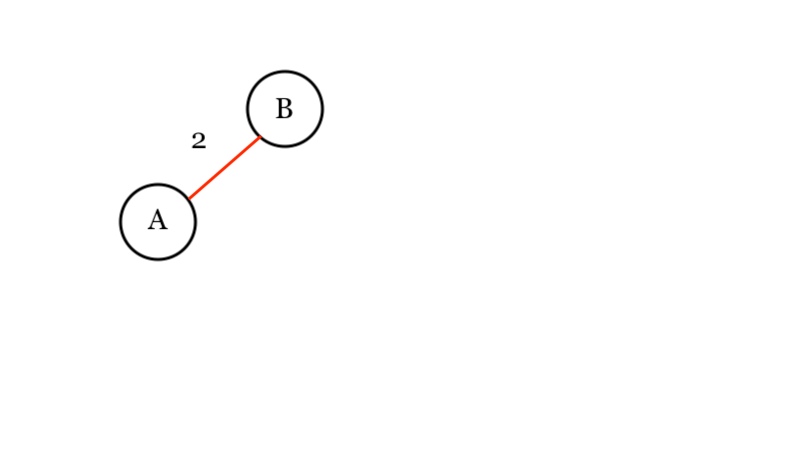
So we get all its edges from the adjacency list. We see that its nodes D(B, 3), C(B, 5), and E(B, 4).
Min Queue: [ C(A, 3), D(B, 3), C(B, 5), E(B, 4) ]
Visited: { “A”, “B” }
Now we see that the number of available paths have increased to four. We then get the minimum path, which is C(A,3). Has C been visited? Nope, we add it to the Visited dictionary. We draw the path in our diagram.
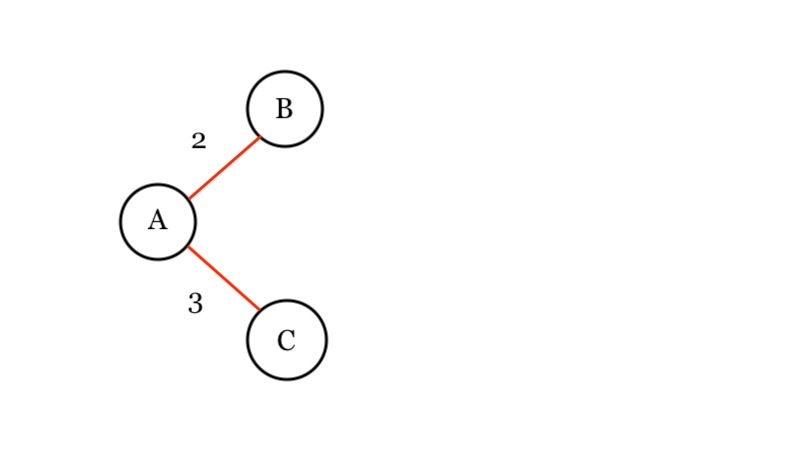
Then we process it by getting all its edges from the adjacency list. We see that it has node of E(C, 4). We push it onto the Min Queue.
Now, we have 4 available paths from nodes A, B, and C.
Min Queue: [ D(B, 3), C(B, 5), E(B, 4), E(C, 4) ]
Visited: { “A”, “B”, “C” }
We get minimum of those paths which is D(B,3). Has D been visited? Nope, we add it to the visited dictionary. We draw the path in our diagram.
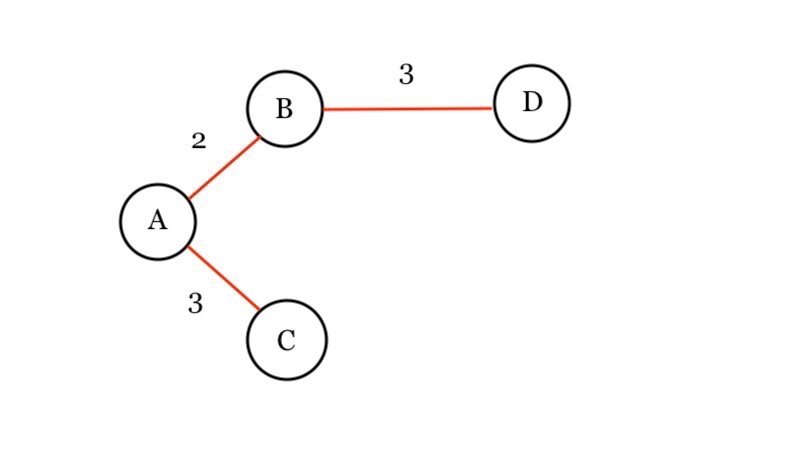
Then we process D by getting all its edges from the adjacency list. We see that it has node of E(D, 2), F(D, 3). We push it onto the Min Queue.
Min Queue: [ C(B, 5), E(B, 4), E(C, 4), E(D, 2), F(D,3) ]
Visited: { “A”, “B”, “C”, “D” }
We pop the minimum of the priority queue: E(D, 2). Has E been visited? Nope, we add it to the visited dictionary. We draw the path in our diagram.
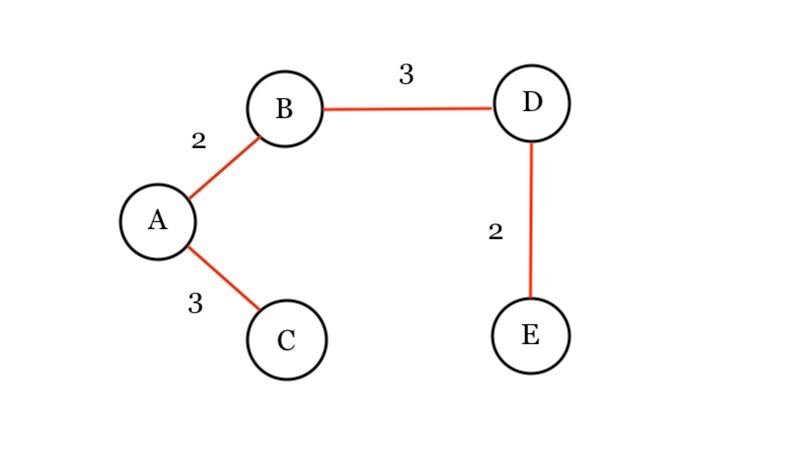
Then we process E by getting all its edges from the adjacency list. We see that it has node of E(F, 5). We push it onto the Min Queue.
Hence at this point, we have 5 available edges from our visited nodes.
Min Queue: [ C(B, 5), E(B, 4), E(C, 4), F(D,3), E(F, 5) ]
Visited: { “A”, “B”, “C”, “D”, “E” }
We pop the minimum which is F(D, 3), and process it. Has F been visited? Nope, we add it to the visited dictionary. We update our answer diagram:
From our adjacency list, we see that F does not have a Linked list of edges. Hence, we DO NOT PUSH ANYTHING onto our Priority Queue:
Min Queue: [ C(B, 5), E(B, 4), E(C, 4), E(F, 5) ]
Visited: { “A”, “B”, “C”, “D”, “E”, “F” }
We keep processing. We pop from the minimum queue: E(B, 4) . Has it been visited? Yes, so we skip and continue dequeueing.
Min Queue: [ C(B, 5), E(C, 4), E(F, 5) ]
Visited: { “A”, “B”, “C”, “D”, “E”, “F” }
We pop from the minimum queue: E(C, 4) . Has it been visited? Yes, so we skip and continue dequeueing.
Min Queue: [ C(B, 5), E(F, 5) ]
Visited: { “A”, “B”, “C”, “D”, “E”, “F” }
We pop from the minimum queue: C(B, 5) . Has it been visited? Yes, so we skip and continue dequeueing.
Min Queue: [ E(F, 5) ]
Visited: { “A”, “B”, “C”, “D”, “E”, “F” }
We pop from the minimum queue: E(F, 5) . Has it been visited? Yes, so we skip it and continue.
Now our queue is empty and we’re done.
The answer is: