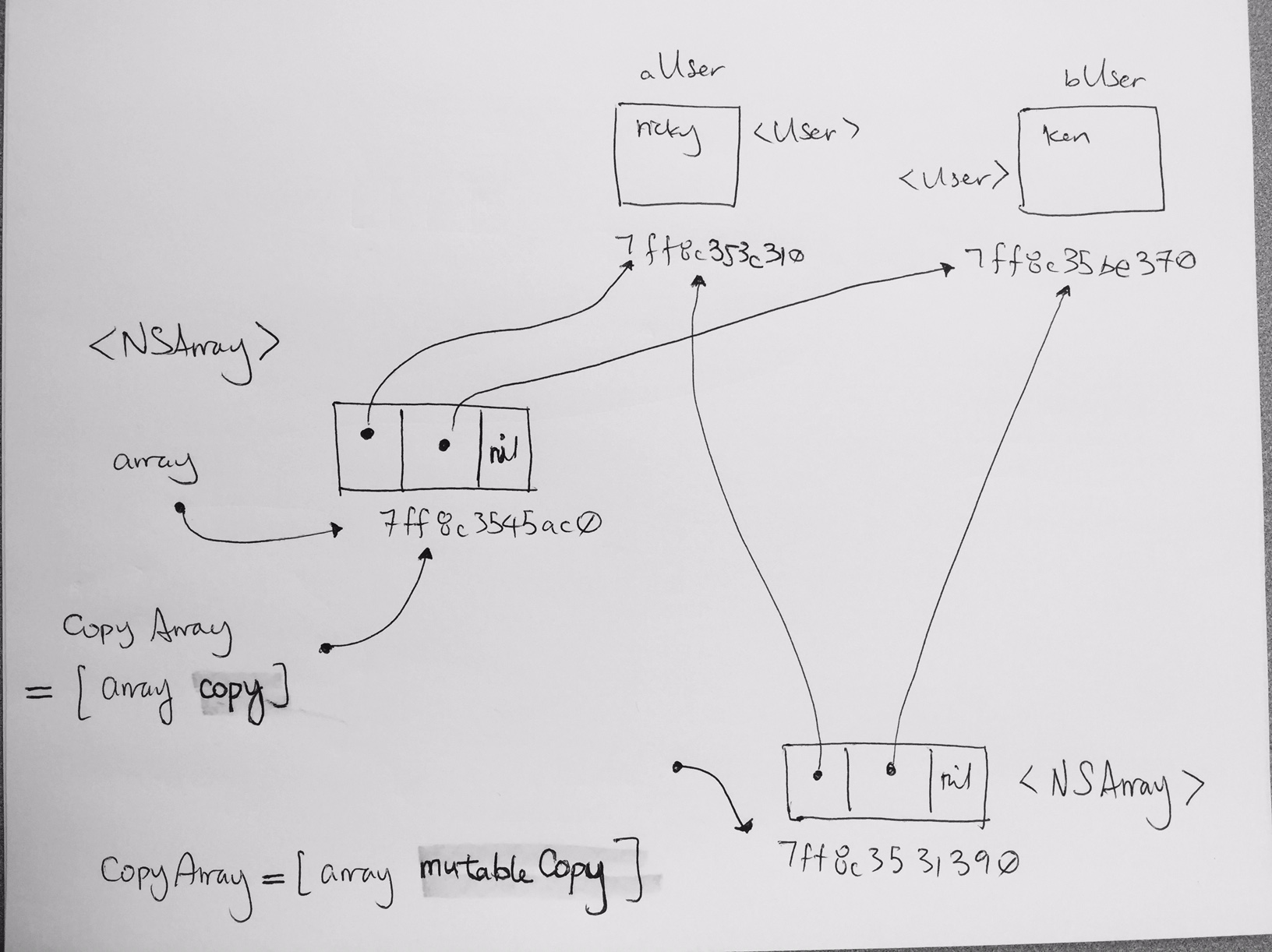
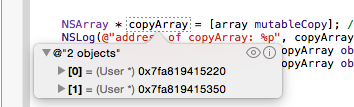
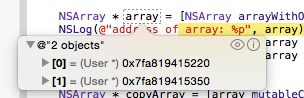
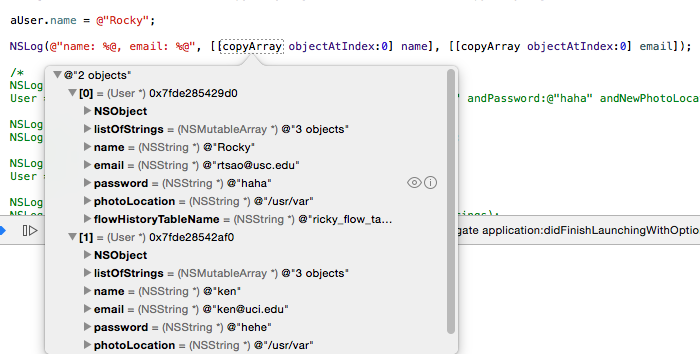
All about braces
variable scope – the places from which a variable is accessible once it has been declared
Block Scope
Objective-C code is divided into sequences of code blocks and files that define the structure of a program. Each block, referred to as a statement block, is encapsulated by braces ({}). For example, a for loop typically contains a statement block:
|
1 2 3 4 5 6 7 |
int x; for (x = 0; x < 10; x++) { int j = x + 10; NSLog (@"j = %i", j); } |
In the above example, variable j is declared within the statement block of the for loop and as such is considered to be local to that block. This means that the variable can be accessed from within the for loop statement block but is essentially invisible and inaccessible to code anywhere else in the program code. Any attempt to access variable j outside the for loop will result in a compile error. For example:
|
1 2 3 4 5 6 7 8 9 |
int x; for (x = 0; x < 10; x++) { int j = x + 10; NSLog (@"j = %i", j); } j += 20; // illegal - j is now out of scope |
2 j’s, different scope
An interesting side effect of variable scope within this context is that it enables us to have more than one variable with the same name as long as they are in different scopes. For example, we can have a variable named j declared outside the for loop and a variable named j declared inside the for loop. Although these variables have the same name they occupy different memory locations and contain different values. This can be illustrated using a simple application that contains two j variables:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
int main (int argc, const char * argv[]) { @autoreleasepool { int x; int j = 54321; for (x = 0; x < 10; x++) { int j = x + 10; NSLog (@"Varible j in for loop is %i", j); } NSLog (@"Variable j outside for loop is %i", j); } return 0; } |
For methods, pass it in, or declare it locally
In terms of variable scope, functions are really little more than statement blocks in that they are encapsulated in braces and variables declared within those braces are local to that function block.
The following example is intended to illustrate this concept and contains two functions named main() and multiply() respectively.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
int main (int argc, const char * argv[]) { @autoreleasepool { int j = 10; int k = 20; int result; result = multiply(); } return 0; } int multiply() { return j * k; } |
The reason for this error is that variables j and k are declared in the main() function and are, therefore, local to that function. As such, these variables are not visible to the multiply() function resulting in an error when we try to reference them. If we wanted to have access to the values of those variables we would have to pass them through as arguments to the multiply function, or specify them locally or globally.