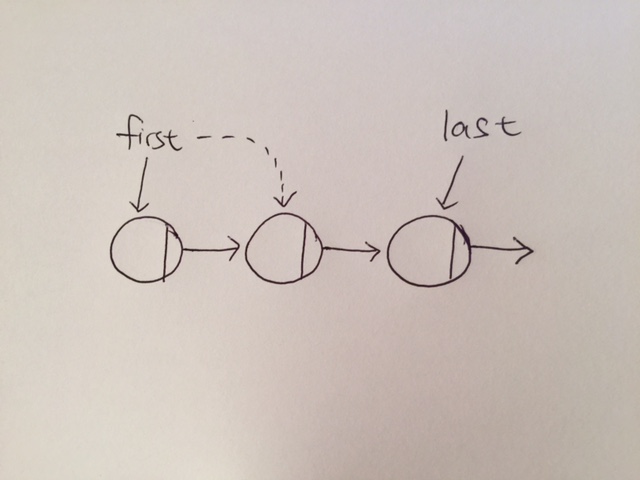
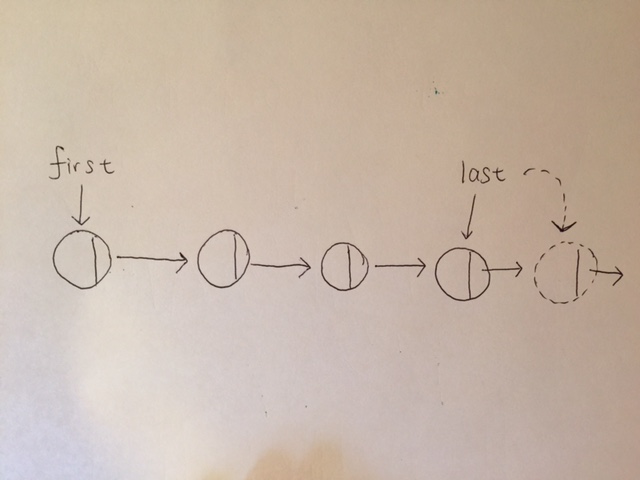In an array, any item can be accessed, either immediately through its index, or by searching through the sequence of cells until its found.
In stacks and queues, however, access is restricted. Only one item can be read or removed at a given time.
Their interface is designed to enforce this restricted access. Theoretically, access to other items are not allowed.
Stacks and Queues are abstract by nature. What I mean by that is that they are defined by their interface. Their underlying workings can be different. For example, A stack may have push, pop, view, etc as its interface. But the underlying mechanism may be an array of a linked list.
Some ways to use Stacks
Reverse a word
Use a stack to reverse a word. When a string of word comes in, push each character into your stack. Then pop the stack onto an empty string, and you will then have the word reversed.
Delimiter Matching
Another common use for stacks is to parse certain kinds of text strings. The delimiters are (, ), [, ], {, }…etc.
You have an empty stack
You have a string say “a{b(c[d]e)f}”
read “a”
“a” != delimiter, go on.
Stack:
read “{”
“{” is opening delimiter, push onto stack.
Stack: {
read “b”
“b” != delimiter, go on.
Stack: {
read “(”
“(” is opening delimiter, push onto stack.
Stack: { (
read “c”
“c” != delimiter, go on.
Stack: { (
read “[”
“[” is opening delimiter, push onto stack.
Stack: { ( [
read “d”
“d” != delimiter, go on.
Stack: { ( [
read “]”
“[” is closing delimiter, pop from stack.
Stack: { (
read “e”
“e” != delimiter, go on.
Stack: { (
read “)”
“)” is closing delimiter, pop from stack.
Stack: {
read “f”
“f” != delimiter, go on.
Stack: {
read “}”
“}” is closing delimiter, pop from stack.
Stack:
Using Queues
Queues are first in first out.
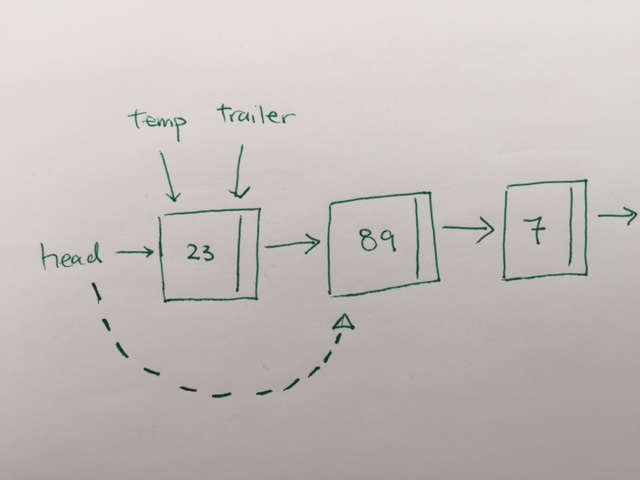
In Arrays, when we insert, we just push onto the array, which is O(1).
When we delete, we remove the 0th element, then push all the elements down, which is O(n).
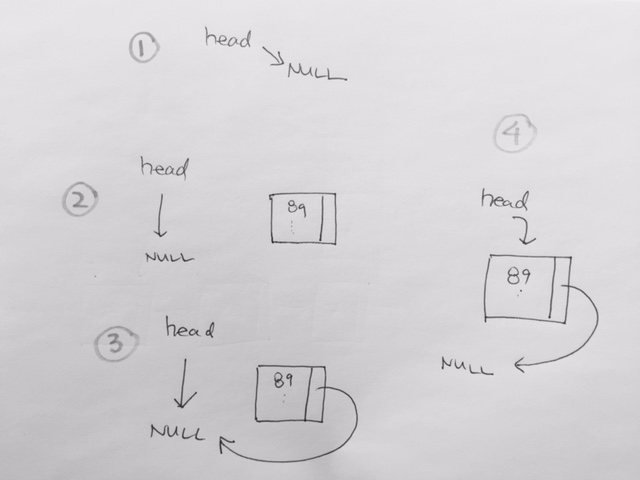
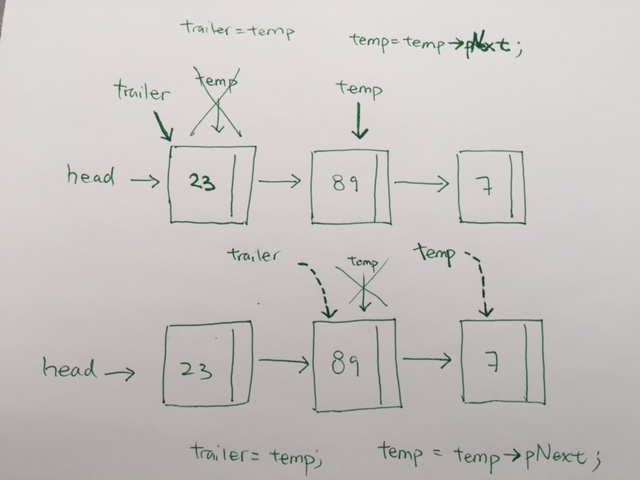
In linked list, we have head and tail pointer. This would make both adding and removing O(1).
However, search and delete would be O(n) because on average, it takes n/2 where n is number of items. T = k * (n/2) where constants are included T = n. In regards to how fast it is to the number of items, we have T = O(n)
priority queues
0 is highest priority, a larger number means a lower priority.
Thus, when we insert an item, we start at the very end of the array. Use a for loop back to 0th index, and see if the new element is larger than the element at the index.
The new element being a larger element means it has a lower priority. If it is, we shift the array element up. We keep doing this until our priority is properly inserted. Having the smallest number mean we have a higher priority, thus, we append the element at the top.
When we delete, we simply pop the top element.