http://javascriptissexy.com/understand-javascript-closures-with-ease/
https://medium.freecodecamp.org/whats-a-javascript-closure-in-plain-english-please-6a1fc1d2ff1c
http://ryanmorr.com/understanding-scope-and-context-in-javascript/
Udemy Example
When I invoke function greet, I’m gunna get a reference to another function, in which I can invoke again.
|
|
function greet(whattosay) { return function(name) { console.log(whattosay + ' ' + name); } } greet('Hi') // returns a function greet('Hi')('Tony') // invoke the returned function var sayHi = greet('Hi'); // 1) sayHi('Tony'); // 2) |
at 1), greet was invoked, so it was pushed then popped from the execution stack.
at 2) when you invoked the returned function object, it still can access variable ‘whattosay’. How is this possible?
First we have the Global Execution Context.
When greet function was invoked, greet() Execution Context was pushed.
The variable that was passed to greet() is sitting in that Execution Context.

We all know that every execution context have memory space reserved for variables and what not. When the execution context gets popped, the memory space presumably also leaves. The JS engine would eventually garbage collect it. However, in our case, in the creation phase of greet()’s context, the variables ‘whattosay’ and the return anon function were stored in memory. The return anon function is a function definiton, and as with any function defintiions, it gets stored in memory.
We invoked sayHi, which is the anon function in memory.
sayHi() Execution Context is pushed onto the context stack.
It runs through the function and are able to use variable ‘whattosay’ because it’s referencing the object that’s existing in memory.

This phenomenon is called ‘the Execution Context has closed in on its outer variables’. It has captured them.
Closure in Memory
Let’s explain the same code, but we’re going to use async capabilities, instead of a returned function.
We start with the same code.
|
|
function greetings() { var name = 'bob'; setTimeout( function() { console.log(`Hi there ${name}`); }, 2000); } |
In the very beginning, we set up the basic. We invoke the global context.
Global (Creation Phase) – which sets up its this, outer references, greetings definition, all in memory
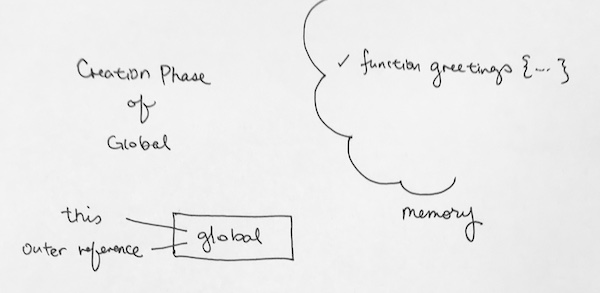
Global (Execution Phase) – During the execution phase, go line by line and execute each line. We first see the function definition greetings. Its already in memory so we skip it. We step and then invoke greetings function. When invoking the function it creates a context, which we push onto the context stack.
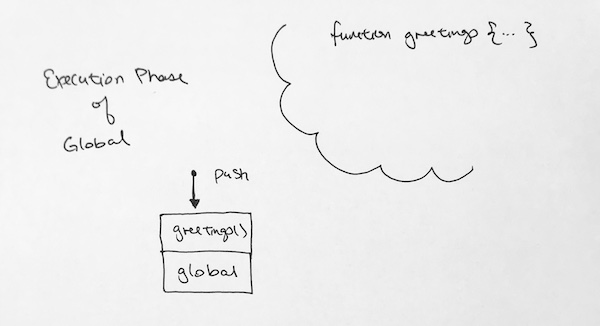
Greetings Context (Creation Phase) – we put variable name into memory and assign it to undefined. We set the ‘this’ reference to the global object, and reference to the outer environment
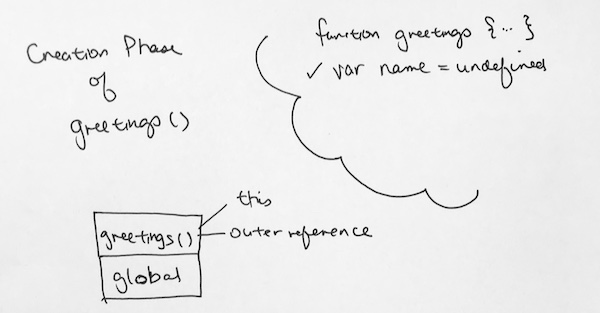
Greetings Context (Execution Phase) – Now comes the line by line execution. Variable name points to immutable literal string ‘ricky’.
Then it invokes setTimeout function. setTimeout function is an async function so it gets put in memory.
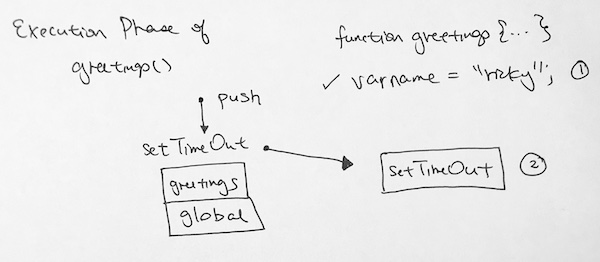
Since the setTimeout function was invoked, it needs to go through creation phase and execution phase.
In the creation phase, it sets up the ‘this’ and outer reference for setTimeout. Then it sees the function definition in the first parameter. It puts that anonymous function in memory.
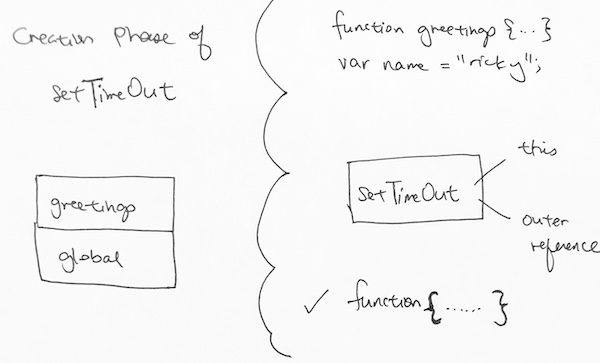
1) For setTimeout’s execution phase, it starts on the “2 second wait”. Once it starts, we continue on to the next step, which is the end of greetings function.
2) The end of greetings function signals that we pop greetings context from the execution stack.
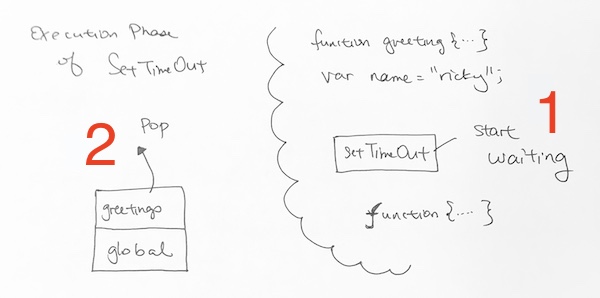
1) Finally, the two seconds are up.
2) setTimeout executes its callback. It invokes the anon function. Thus, it gets pushed onto the context stack.
3) setTmeout completes and thus, gets removed from memory.
then,
1) The invocation of the anon function goes through its Creation Phase. There’s literally nothing there except a log. However, we see that in the log, we are referencing name variable from the memory.
2) We print the log statement
3) the anon function now finishes is popped off the context stack.
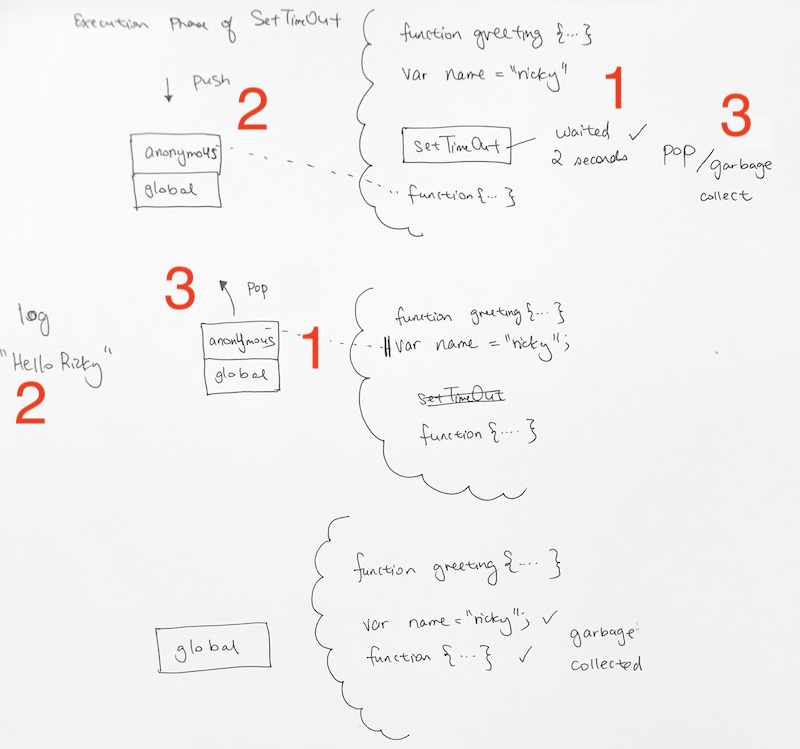
In the end, only the global context is left. In memroy, since nothing else is using name, nor anon function in this context, they will be garbage collected.
What is a closure?
Closure is the act of capturing an object and separating it from its original scope, making it available to the capturing function forever.
First off, you create a closure whenever you define a function, NOT when you execute it.
In other words, a closure is formed when a nested function is defined inside of another function, allowing access to the outer functions variables.
For example,
returning the inner function allows you to maintain references to the local variables, arguments, and inner function declarations of its outer function
This encapsulation allows us to:
1) hide and preserve the execution context from outside scopes
2) while exposing a public interface and thus is subject to further manipulation.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
var helloStr = 'world'; var sayHello = function(name) { console.log('-- anonoymous function --'); console.log('name parameter is: ' + name); return function() { console.log('-- returned function --'); console.log('Hello ' + name + '!'); } } // 1) executes sayHello function. // 2) 'world' is passed in. // 3) returns inner function. Not executed yet. No scope created. var sayGreeting = sayHello(helloStr); sayGreeting(); // 'Hello world' // 1) inner function executes. scope created // 2) accesses local parameter name 'world'. |
setTimeout example
First Try…
We’re accessing the i from the outside scope’s for loop via parent scope.
|
|
// step 1 for (var i = 0; i < 10; i++) { // 1) runs through the i console.log(i); // 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 // at this point, i is 10 // 2) after 1 second, then it would execute the callback function setTimeout(function() { // 3) displays the checkmark and 10s console.log(i); // 10 }, 1000); } |
The result is:
0
1
2
3
4
5
6
7
8
9
1 second later…
10
10
10
10
10
10
not really what we want…
2nd try
We wrap an IIFE around it so that we save the index variable. Now, for each setTimeout invocation at each index i,
we have successfully saved i into parameter index. Each Execution Context is pushed on with the index variable.
Then the setTimeout inside will be able to access the index variable.
|
|
(function(index) { setTimeout(function() { console.log('callback: ' + index); }, 3000); // i's value is received via scoping when the callback fun executes. })(i) |
for loop: 0
for loop: 1
for loop: 2
for loop: 3
…
…
AFTER 3 SECONDs…
callback: 0
callback: 1
callback: 2
One of the most popular types of closures is what is widely known as the module pattern; it allows you to emulate public, private, and privileged members:
Module Pattern
The module acts as if it were a singleton, executed as soon as the compiler interprets it, hence the opening and closing parenthesis at the end of the function. The only available members outside of the execution context of the closure are your public methods and properties located in the return object (Module.publicMethod for example). However, all private properties and methods will live throughout the life of the application as the execution context is preserved, meaning variables are subject to further interaction via the public methods.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
// Module is a singleton // due to self invoked anonymous function returned as singleton, // it is executed as soon as the compiler interprets it. var Module = (function() { var privateProperty = 'foo'; function privateMethod(args) { // do something console.log("privateMethod"); console.log("private property is: " + privateProperty) } function anotherPrivateFunc() { console.log('helooooooo'); } return { publicProperty: '', refToAPrivateFunc: anotherPrivateFunc, publicMethod: function(args) { // do something console.log("publicMethod"); }, privilegedMethod: function(args) { console.log("privilegedMethod"); return privateMethod(args); } }; })(); Module.publicMethod(null) Module.privilegedMethod(null) Module.refToAPrivateFunc(); // heloooooo |
or executed in the context of the window object:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
(function(window) { var foo, bar; function private() { // do something console.log("private function! :D") } window.Module2 = { public: function() { // do something console.log("public function!") } }; })(this); this.Module2.public(); |
The closure has three scope chains
– it has access to its own scope (local variables)
– it has access to the outer function’s variables (including parameters)
– and it has access to the global variables.
When you put a function in a variable like this, you are assigning the variable func, a reference to the function sayHello, NOT A COPY.
Via definition of a reference, anything you do on the func reference will be done on the original function.
|
|
function sayHello() { console.log("hello"); }; var func = sayHello; |
For example, when we add a property to reference func:
our function sayHello will also have it because func is a reference to sayHello.
|
|
console.log(sayHello.answer); // 42 |
Lexical Scoping
Describes how a parser resolves variable names when functions are nested. The word “lexical” refers to the fact that lexical scoping uses the location where a variable is declared within the source code to determine where that variable is available.
Nested functions have access to variables declared in their outer scope.
|
|
function init() { var name = 'Mozilla'; // name is a local variable created by init function displayName() { // displayName() is the inner function, a closure alert(name); // use variable declared in the parent function } displayName(); } init(); |
init() creates a local variable called name and a function called displayName().
The displayName() function is an inner function that is defined inside init() and is only available within the body of the init() function.
The displayName() function has no local variables of its own.
However, because inner functions have access to the variables of outer functions, displayName() can access the variable name declared in the parent function, init().
However, the same local variables in displayName() will be used if they exist.
Run the code and notice that the alert() statement within the displayName() function successfully displays the value of the name variable, which is declared in its parent function.
Scope is created when you execute a function
When you call a function like init() you create a scope during the execution of that function. Then that scope goes away.
When you call the function a second time, you create a new different scope during the second execution. Then this second goes away as well.
|
|
function printA() { console.log(answer); var answer = 1; }; printA(); // this creates a scope which gets discarded right after printA(); // this creates a new different scope which also gets discarded right after; |
These two scopes that were created in the example above are different. The variable answer here is not shared between them at all.
Every function scope has a lifetime. They get created and they get discarded right away. The only exception to this fact is the global scope, which does not go away as long as the application is running.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
// functions form closures. // a closure is the combination of a function and // the lexical environment within which that // function was declared. function makeFunc() { var name = 'Mozilla'; function displayName() { console.log(name); } return displayName; // return the function so outer context can use it } // in this case, myFunc is a reference to the instance // of the function displayName. // instance of displayName maintains a reference to its // lexical environment, within which the variable name exists. var myFunc = makeFunc(); // Instance of displayName is returned // for this reason, when myFunc is invoked, the variable 'name' remains available for // use and mozilla is passed to log. myFunc(); |
Closures are created when you DEFINE a function
When you define a function, a closure gets created.
Unlike scopes, closures are created when you DEFINE a function, NOT when you execute it. Closures don’t go away after you execute that function.
local scope, parent scope, and global scope are all referenced by the closure. NOT COPIED:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
var G = 'G'; // Define a function and create a closure function functionA() { var A = 'A' // Define a function // create a closure that can access scope of // functionB, scope of functionA(), plus global scope. // closures gives us a reference to var B, A, and G. function functionB() { var B = 'B' console.log(A, B, G); } // execute functionB, create scope functionB(); // prints A, B, G // functionB closure does not get discarded A = 42; // execute functionB, create scope functionB(); // prints 42, B, G } // execute functionA, create scope functionA(); |
Don’t confuse closures with scopes
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
// scope: global var a = 1; void function one() { // scope: one // closure: [one, global] var b = 2; void function two() { // scope: two // closure: [two, one, global] var c = 3; void function three() { // scope: three // closure: [three, two, one, global] var d = 4; console.log(a + b + c + d); // prints 10 }(); }(); }(); |
In the simple example above, we have three functions and they all get defined and immediately invoked, so they all create scopes and closures.
The scope of function one() is its body. Its closure gives us access to both its scope and the global scope.
The scope of function two() is its body. Its closure gives us access to its scope plus the scope of function one()plus the global scope
And similarly, the closure of function three() gives us access to all scopes in the example. This is why we were able to access all variables in function three().
Another Example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
// global scope var v = 1; // 1) f1 defined. closure here, plus global scope. the v accesses global v = 1. var f1 = function () { // 6) scope is within this body. // 7) from closure, v will access 1. console.log(v); // 8) prints 1 } // 2) f2 defined. closure here, plus global scope. However, var v is local v = 2. var f2 = function() { // 4) scope is within its body var v = 2; f1(); // 5) create scope }; f2(); // 3) create scope |
If not global variable v…
|
|
var f1 = function () { console.log(v); } var f2 = function() { var v = 2; f1(); // ReferenceError: v is not defined }; f2(); |
Since closures have REFERENCE to variables in scope, they have read/write access
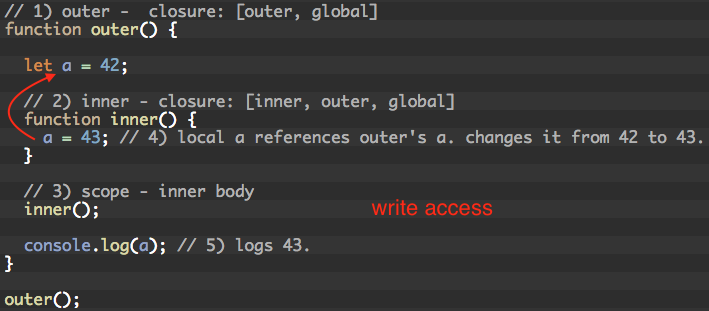
This is why we can change global variables everywhere. All closures give us both read/write access to all global variables.
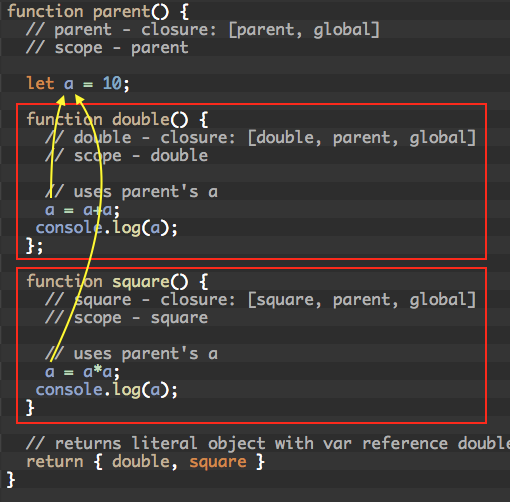
Closures can share scopes
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
function parent() { // parent - closure: [parent, global] // scope - parent let a = 10; function double() { // double - closure: [double, parent, global] // scope - double // uses parent's a a = a+a; console.log(a); }; function square() { // square - closure: [square, parent, global] // scope - square // uses parent's a a = a*a; console.log(a); } // returns literal object with var reference double and square to functions double and square return { double, square } } // executes parent() let { double, square } = parent(); double(); // prints 20 square(); // prints 400 double(); // prints 800 |
double and square both share scope parent. This means their closure references variables from parent. Specifically, variable a.
Hence, when we call double the first time, double references var a from parent. It does 10 + 10 = 20. Parent’s var a is now 20.
Then, square references var a from parent. a is now 20 from the call to double due to reference usage. square does 20 * 20 = 400.
Parent’s a is now 400.
We execute double again. double’s closure references a from parent which is 400. It does 400 + 400 = 800. Parent’s var a is now 800.
Another example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
// 1) global var a initialized to 1 let a = 1; // func1 closure - [func1, global] const func1 = function() { console.log(a); // 4) a was set to log 3 since execution is top to bottom a = 2 // 5) references global a. set to 2. } a = 3; // 2) global var a set to 3 // func2 closure - [func2, global] const func2 = function() { // 7) references global a, which was set to 2. console.log(a); // 8) logs 2 } // 3) execute func1, scope is func1 body func1(); // 6) execute func2, scope is func2 body func2(); |
output:
3
2
Things can get weird though – People Example
Here we pass an array of objects into a function. We are expecting this function to update property id of our objects.
|
|
var gang = [ {name: 'tsao', id: undefined}, {name: 'scar', id: undefined}, {name: 'qian qian', id: undefined} ]; var updatedGang = creator(gang); |
We use a loop to assign index to the array element’s id property.
The anonymous function created here is stored in heap memory, as well as the var i.
|
|
function creator(people) { var i; for (i=0; i < people.length; i++) { people[i]["id"] = function() { return (i+100); } } return people; } // creator |
After we run this, the result id are all the same, 103.
|
|
console.log(updatedGang[0].id()) // 103 console.log(updatedGang[1].id()) // 103 console.log(updatedGang[2].id()) // 103 |
Since var i, and all three anon functions are stored in heap memory, when we try to access the ids later in the future, the var i is already 103.
Thus, when you invoke those functions in the future, they will be access i that is 103.
Solution
We need to make sure we store the correct i somehow, and not an i that has already ran through its course to the end.
We do this through two ways:
- Invoking the function and storing the value right away
- IIFE
- “let”
Invoke the function, and storing the value
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
var gang = [ {name: 'tsao', id: undefined}, {name: 'scar', id: undefined}, {name: 'qian qian', id: undefined} ]; function creator(people) { var i; for (i=0; i < people.length; i++) { // declare function with parameter j people[i]["id"] = function(j) { console.log('Calculating for index: ' + j); return (j+100); }(i); // then call it right away and pass in i. // the result is then stored in people[i]["id"] right away } return people; } // creator var updatedGang = creator(gang); // Calculating for index: 0 // Calculating for index: 1 // Calculating for index: 2 |
This is about invoking the function right away, and then assigning the value to people[i][“id”].
As you can see when you call creator(gang), the logs ‘Calculating for index:…’ gets called right away.
Because at each index, the anonymous function gets invoked and then the value is stored.
Thus, whenever you access updatedGang[0].id, you’re simply retrieving the stored value
|
|
console.log(updatedGang[0].id) // 100 console.log(updatedGang[1].id) // 101 console.log(updatedGang[2].id) // 102 |
In this solution, we’re invoking the function RIGHT AWAY, thus creating the scope, and the i is accessed. It will return 0. 0 + 100 = 100. It will then assign the integer 100 to updatedGang[0].id
When i becomes 1, the function executes RIGHT AWAY, creating the scope, and the i is accessed as 1. 1 + 100 = 101. 101 gets assigned to updatedGang[1].id.
… and so on.
using IIFE
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
function creator(people) { var i; for (i = 0; i < people.length; i++) { (function(index) { people[i]["id"] = function() { console.log('-- result --'); console.log(index + 100); } })(i); } } var updatedGang = creator(gang); updatedGang[0].id() // -- result -- 100 updatedGang[1].id() // -- result -- 101 updatedGang[2].id() // -- result -- 102 |
As you can see, we now have reference to a function that you can execute in the future. In addition, we also have our own variable ‘index’ to store the i.
The IIFE for index 0 puts the i in its own memory, and stores it.
The IIFE for index 1 puts the i in its own memory, and stores it
…etc
Thus, we can invoke on the fly and still get the correct answer. It is vastly different than our previous example, which is invoke right away, and storing the result.
In other words:
Using IIFE, we first create a function expression and invoke it immediately with a parameter. This creates a context that gets pushed onto our stack context.
Creation Phase:
– We point this reference to global object.
– We create outer reference to scope
– puts parameter ‘index’ in memory
– put anon function j in memory.
Execution Phase:
– We use scope to access people and i. We assign them to anon function which is in memory. This anon function will access parameter ‘index’, which is also stored in memory.
Then this IIFE gets popped from the context stack.
When this loop is done, creator context is popped from the stack.
In the future, when you try to access updatedGang[1].id(), you execute this anon function that is stored in memory. It has index as 1, which is also stored in memory.
Hence that is the reason why we’re able to get the correct value at a later time. We store everything in memory via function definitions and variables.
Using let (block scoped)
We need to use let to make sure we get correct scoping.
A variable declared by let or const has a so-called temporal dead zone (TDZ): When entering its scope, it can’t be accessed (got or set) until execution reaches the declaration.
i in the inner function is not referencing some global var i. It it referencing a block scope variable i, which has been pushed onto the local stack.
|
|
function creator(people) { for (let i=0; i < people.length; i++) { people[i]["id"] = function() { return (i+100); } } return people; } // creator |
it works because, for (let i = 0; i < arr.length ;i ++) defines i as var i for the local block.
in addition:
ref – http://chineseruleof8.com/code/index.php/2017/10/01/let-vs-var-js/
i is only visible in here (and in the for() parentheses)
and there is a SEPARATE i var for each iteration of the loop
like this:
|
|
for (let i = 0; i < people.length; i++) |
does this:
|
|
{ var i = 0; people[i]["id"] = function() { return (i+100); } } |
|
|
{ var i = 1; people[i]["id"] = function() { return (i+100); } } |
|
|
{ var i = 2; people[i]["id"] = function() { return (i+100); } } |
Hence when we call people[0].id(), we evaluate i, which accesses its local var i as 0. 0 + 100 = 100.
people[1].id(), we evaluate the i, which accesses its local var i as 1. 1 + 100 = 101.
… so on.
Another example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
function setupSomeGlobals() { // Function definition declarations are hoisted. var num = 666; gLogNumber = function() { // function expressions are not hoisted console.log(num); } gIncreaseNumber = function() { num++; } gSetNumber = function(x) { num = x; } } // undeclared variable in function context is global // new stack A setupSomeGlobals(); // that's why after executing setupSomeGlobals, we have scope, in which the // undeclared names are considered global variables. That's why we can use // them below gIncreaseNumber(); gLogNumber(); // 667 gSetNumber(5); gLogNumber(); // 5 var oldLog = gLogNumber; // new stack B setupSomeGlobals(); gLogNumber(); // 666 oldLog() // 5. oldLog references the stack A's gLogNumber. Thus, the num in that stack is 5. |