Create REST API with Typescript
mkdir Und-TSC-sec15
cd Und-TSC-sec15
Create Node Project
npm init
You’ll then have a package.json file.
|
1 |
tsc --init |
You’ll then have a tsconfig.json file.
In tsconfig.json:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
{ "compilerOptions": { /* Visit https://aka.ms/tsconfig.json to read more about this file */ /* Basic Options */ // "incremental": true, /* Enable incremental compilation */ "target": "es2018", /* Specify ECMAScript target version: 'ES3' (default), 'ES5', 'ES2015', 'ES2016', 'ES2017', 'ES2018', 'ES2019', 'ES2020', or 'ESNEXT'. */ "module": "commonjs", /* Specify module code generation: 'none', 'commonjs', 'amd', 'system', 'umd', 'es2015', 'es2020', or 'ESNext'. */ "moduleResolution": "node", "lib": [ "dom", "es6", "dom.iterable", "scripthost" ], /* Specify library files to be included in the compilation. */ "sourceMap": true, /* Generates corresponding '.map' file. */ // "outFile": "./", /* Concatenate and emit output to single file. */ "outDir": "./dist", /* Redirect output structure to the directory. */ "rootDir": "./src", /* Specify the root directory of input files. Use to control the output directory structure with --outDir. */ // "composite": true, /* Enable project compilation */ // "tsBuildInfoFile": "./", /* Specify file to store incremental compilation information */ "removeComments": true, /* Do not emit comments to output. */ // "noEmit": true, /* Do not emit outputs. */ // "importHelpers": true, /* Import emit helpers from 'tslib'. */ // "downlevelIteration": true, /* Provide full support for iterables in 'for-of', spread, and destructuring when targeting 'ES5' or 'ES3'. */ // "isolatedModules": true, /* Transpile each file as a separate module (similar to 'ts.transpileModule'). */ /* Strict Type-Checking Options */ "strict": true, /* Enable all strict type-checking options. */ "noImplicitReturns": true, /* Report error when not all code paths in function return a value. */ // "noFallthroughCasesInSwitch": true, /* Report errors for fallthrough cases in switch statement. */ // "noUncheckedIndexedAccess": true, /* Include 'undefined' in index signature results "typeRoots": [ "node_modules/@types" ], /* List of folders to include type definitions from. */ // "types": [], /* Type declaration files to be included in compilation. */ // "allowSyntheticDefaultImports": true, /* Allow default imports from modules with no default export. This does not affect code emit, just typechecking. */ "esModuleInterop": true, /* Enables emit interoperability between CommonJS and ES Modules via creation of namespace objects for all imports. Implies 'allowSyntheticDefaultImports'. */ } } |
Now let’s install the needed modules:
standard web server independencies:
npm install –save express body-parser
development independencies:
npm install –save-dev nodemon
create src folder:
mkdir src
cd src
touch app.ts
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import express from 'express'; import { json } from 'body-parser'; const app = express(); app.use(json()); app.get('/', (req, res)=> { console.log('entered root endpoint'); res.status(400).send('Welcome to Guang Dong!'); }); // error handling middleware function app.use((err: Error, req: express.Request, res: express.Response, next: express.NextFunction) => { res.status(500).json({message: err.message}); }); app.listen(3000); |
When you are done, type tsc to compile the typescript into javascript.
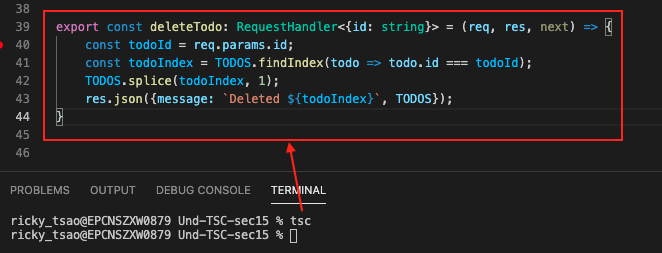
Then you can debug it. Put a breakpoint there and make sure you’re on the index file. In our file, we’re on app.ts.
Once you’re on that file, go to Run > Start Debugging. You’ll see the bottom status bar turn orange. This means the server is running.
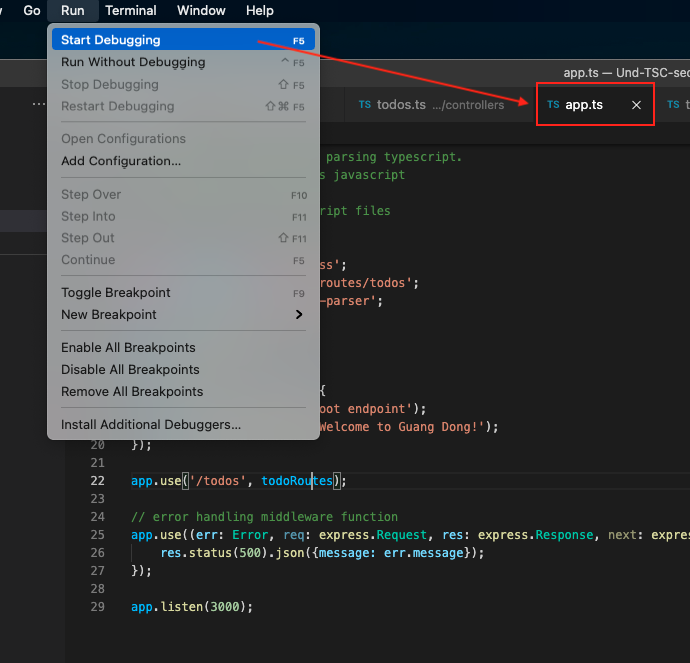
Click on View > Terminal, and you’ll see the terminal pop up. Then click on debug console. You’ll be able to see the console log from the node js app appear.
Creating Routes
cd src/routes
touch todos.ts
We extract Router from express. We can then register routes to hit functionality.
We set up the router to receive POST, GET, PATCH, and DELETE on ‘/’.
Each HTTP request will get mapped to certain functionalities that we declare in controllers/todos file.
routes/todos.ts
|
1 2 3 4 5 6 7 8 9 10 |
import { Router } from 'express'; import { createTodo, getTodos, updateTodo, deleteTodo} from '../controllers/todos'; const router = Router(); router.post('/', createTodo); router.get('/', getTodos); router.patch('/:id', updateTodo); router.delete('/:id', deleteTodo); export default router; |
Finally, we need to connect our router to our server for endpoint /todos.
app.ts
|
1 2 3 4 5 6 7 8 9 10 |
import express from 'express'; import todoRoutes from './routes/todos'; const app = express(); app.use('/todos', todoRoutes); // localhost:3000/todos will hit todoRoutes // depending on what HTTP verb it is, it will hit the functionalities mapped to that verb. // error handling middleware function app.use((err: Error, req: express.Request, res: express.Response, next: express.NextFunction) => { res.status(500).json({message: err.message}); }); |
Add additional routes
First, we create a class Todos so we have a structure to work with. We export a class Todo so other modules can import it, and then new it to create an instance of Todo.
|
1 2 3 4 5 |
export class Todo { constructor(public id: string, public text: string) { console.log('Constructingn a Todo instance...'); } } |
Then import the class so that we get a simple data structure going.
We create functionality by implementing a function createTodo.
Note that we use RequestHandler interface, which contracts us to use
req, res, and next parameters.
controllers/todo.ts
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import { RequestHandler } from 'express'; import { Todo } from '../models/todo'; // TODOS is the name of an array of type Todo const TODOS: Todo [] = []; export const createTodo: RequestHandler = (req, res, next) => { console.log('entered createTodo'); const text = (req.body as {text:string}).text; console.log('text', text); const newTodo = new Todo(Math.random().toString(), text); TODOS.push(newTodo); res.status(201).json({ message: 'Created the todo', createdTodo: newTodo }) }; |
Since it takes care of a POST request, we use parse the body property in the request
object to get the body data. The body data’s key is text.
In order do that we need to import the body-parser package in app.ts, and then extract json.
This is so that we parse the body using json.
app.ts
|
1 2 3 4 |
import { json } from 'body-parser'; ... ... app.use(json()); |
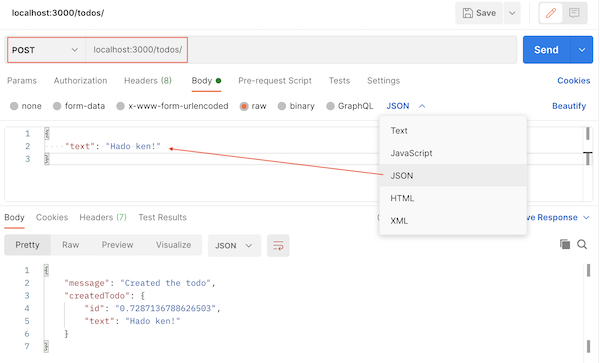
Open up your postman and query it like so: